- Apr 24, 2024
-
-
Alexandru Gheorghe authored
Part of https://github.com/paritytech/polkadot-sdk/issues/4126 we want to safely increase the execute_workers_max_num gradually from chain to chain and assess if there are any negative impacts. This PR performs the necessary plumbing to be able to increase it based on the chain id, it increase the number of execution workers from 2 to 4 on test network but lives kusama and polkadot unchanged until we gather more data. --------- Signed-off-by:Alexandru Gheorghe <[email protected]>
-
- Apr 23, 2024
-
-
AlexWang authored
This is for adding onfinality polkadot bootnode. Please correct me if this is not the right place for adding a new bootnode
-
Alexandru Gheorghe authored
Add a metric to be able to understand the time jobs are waiting in the execution queue waiting for an available worker. https://github.com/paritytech/polkadot-sdk/issues/4126 Signed-off-by:
-
- Apr 22, 2024
-
-
Andrei Eres authored
-
Andrei Eres authored
Co-authored-by:alvicsam <[email protected]>
-
- Apr 19, 2024
-
-
maksimryndin authored
follow up of https://github.com/paritytech/polkadot-sdk/pull/2604 closes https://github.com/paritytech/polkadot-sdk/pull/2604 - [x] take relevant changes from Marcin's PR - [x] extract common duplicate code for workers (low-hanging fruits) ~Some unpassed ci problems are more general and should be fixed in master (see https://github.com/paritytech/polkadot-sdk/pull/4074)~ Proposed labels: **T0-node**, **R0-silent**, **I4-refactor** ----- kusama address: FZXVQLqLbFV2otNXs6BMnNch54CFJ1idpWwjMb3Z8fTLQC6 --------- Co-authored-by:s0me0ne-unkn0wn <[email protected]>
-
Andrei Sandu authored
Related to https://github.com/paritytech/polkadot-sdk/issues/4126 discussion Currently all preparations have same priority and this is not ideal in all cases. This change should improve the finality time in the context of on-demand parachains and when `ExecutorParams` are updated on-chain and a rebuild of all artifacts is required. The desired effect is to speed up approval and dispute PVF executions which require preparation and delay backing executions which require preparation. --------- Signed-off-by:Andrei Sandu <[email protected]>
-
Andrei Eres authored
- Returned latency (with it, results are more stable) - The threshold is weakened - Increased number of runs
-
- Apr 18, 2024
-
-
Alexandru Gheorghe authored
approval-voting: Make sure we always mark approved candidates approved in a different relay chain context (#4153) ... see for more detail why this is needed https://github.com/paritytech/polkadot-sdk/issues/4149#issuecomment-2058472444 ## TODO: - [x] Unittests - [x] Replicate scenario from https://github.com/paritytech/polkadot-sdk/issues/4149 and confirm this fixes it: https://github.com/paritytech/polkadot-sdk/issues/4149 [ Replicated on a zombienet with some hacked nodes, that we can end up in this state where no-wake is schedule and the nodes are pending new assignments] --------- Signed-off-by:
Andrei Sandu <[email protected]>
-
Alexandru Gheorghe authored
The `next_retry_time` gets populated when a request receives an error timeout or any other error, after thatn next_retry would check all requests in the queue returns the smallest one, which then gets used to move the main loop by creating a Delay ``` futures_timer::Delay::new(instant.saturating_duration_since(Instant::now())).await, ``` However when we retry a task for the first time we still keep it in the queue an mark it as in flight so its next_retry_time would be the oldest and it would be small than `now`, so the Delay will always triggers, so that would make the main loop essentially busy wait untill we received a response for the retry request. Fix this by excluding the tasks that are already in-flight. --------- Signed-off-by:
-
-
Alexander Samusev authored
cc https://github.com/paritytech/ci_cd/issues/974 --------- Co-authored-by: command-bot <> Co-authored-by:Bastian Köcher <[email protected]>
-
- Apr 16, 2024
-
-
Alin Dima authored
Will make https://github.com/paritytech/polkadot-sdk/pull/4035 easier to review (the mentioned PR already does this move so the diff will be clearer). Also called out as part of: https://github.com/paritytech/polkadot-sdk/pull/3233#discussion_r1490867383
-
- Apr 14, 2024
-
-
Jonathan Udd authored
Verified by running a node using `--reserved-only` and `--reserved-nodes`.
-
- Apr 12, 2024
-
-
Andrei Sandu authored
Fixes https://github.com/paritytech/polkadot-sdk/issues/3576 Required by elastic scaling collators. Deprecates old API: `candidate_pending_availability`. TODO: - [x] PRDoc --------- Signed-off-by:
-
- Apr 11, 2024
-
-
Andrei Eres authored
Implements the idea from https://github.com/paritytech/polkadot-sdk/pull/3899 - Removed latencies - Number of runs reduced from 50 to 5, according to local runs it's quite enough - Network message is always sent in a spawned task, even if latency is zero. Without it, CPU time sometimes spikes. - Removed the `testnet` profile because we probably don't need that debug additions. After the local tests I can't say that it brings a significant improvement in the stability of the results. However, I belive it is worth trying and looking at the results over time.
-
Andrei Sandu authored
fixes https://github.com/paritytech/polkadot-sdk/issues/4067 Also add an early bail out for look ahead collator such that we don't waste time if a CollatorFn is not set. TODO: - [x] add test. - [x] Polkadot System Parachain burn-in. --------- Signed-off-by:
-
- Apr 10, 2024
-
-
Alexandru Vasile authored
This tiny PR extends the `on_validated_block_announce` log with the bad PeerID. Used to identify if the peerID is malicious by correlating with other logs (ie peer-set). While at it, have removed the `\n` from a multiline log, which did not play well with [sub-triage-logs](https://github.com/lexnv/sub-triage-logs/tree/master). cc @paritytech/networking --------- Signed-off-by:
Alexandru Vasile <[email protected]> Co-authored-by:
Bastian Köcher <[email protected]>
-
Egor_P authored
This PR backports `spec_version`, `node_version` bumps and reordering of the prdocs from the 1.10.0 release branch
-
- Apr 08, 2024
-
-
Aaro Altonen authored
[litep2p](https://github.com/altonen/litep2p) is a libp2p-compatible P2P networking library. It supports all of the features of `rust-libp2p` that are currently being utilized by Polkadot SDK. Compared to `rust-libp2p`, `litep2p` has a quite different architecture which is why the new `litep2p` network backend is only able to use a little of the existing code in `sc-network`. The design has been mainly influenced by how we'd wish to structure our networking-related code in Polkadot SDK: independent higher-levels protocols directly communicating with the network over links that support bidirectional backpressure. A good example would be `NotificationHandle`/`RequestResponseHandle` abstractions which allow, e.g., `SyncingEngine` to directly communicate with peers to announce/request blocks. I've tried running `polkadot --network-backend litep2p` with a few different peer configurations and there is a noticeable reduction in networking CPU usage. For high load (`...
-
Tsvetomir Dimitrov authored
With Coretime enabled we can no longer assume there is a static 1:1 mapping between core index and para id. This mapping should be obtained from the scheduler/claimqueue on block by block basis. This PR modifies `para_id()` (from `CoreState`) to return the scheduled `ParaId` for occupied cores and removes its usages in the code. Closes https://github.com/paritytech/polkadot-sdk/issues/3948 --------- Co-authored-by: -
HongKuang authored
Signed-off-by:hongkuang <[email protected]>
-
- Apr 05, 2024
-
-
divdeploy authored
Signed-off-by:divdeploy <[email protected]>
-
- Apr 04, 2024
-
-
 Michal Kucharczyk authored
Michal Kucharczyk authoredThe runtime now can provide a number of predefined presets of `RuntimeGenesisConfig` struct. This presets are intended to be used in different deployments, e.g.: `local`, `staging`, etc, and should be included into the corresponding chain-specs. Having `GenesisConfig` presets in runtime allows to fully decouple node from runtime types (the problem is described in #1984). **Summary of changes:** - The `GenesisBuilder` API was adjusted to enable this functionality (and provide better naming - #150): ```rust fn preset_names() -> Vec<PresetId>; fn get_preset(id: Option<PresetId>) -> Option<serde_json::Value>; //`None` means default fn build_state(value: serde_json::Value); pub struct PresetId(Vec<u8>); ``` - **Breaking change**: Old `create_default_config` method was removed, `build_config` was renamed to `build_state`. As a consequence a node won't be able to interact with genesis config for older runtimes. The cleanup was made for sake of API simplicity. Also IMO maintaining compatibility with old API is not so crucial. - Reference implementation was provided for `substrate-test-runtime` and `rococo` runtimes. For rococo new [`genesis_configs_presets`](https://github.com/paritytech/polkadot-sdk/blob/3b41d66b/polkadot/runtime/rococo/src/genesis_config_presets.rs#L530) module was added and is used in `GenesisBuilder` [_presets-related_](https://github.com/paritytech/polkadot-sdk/blob/3b41d66b/polkadot/runtime/rococo/src/lib.rs#L2462-L2485) methods. - The `chain-spec-builder` util was also improved and allows to ([_doc_](https://github.com/paritytech/polkadot-sdk/blob/3b41d66b/substrate/bin/utils/chain-spec-builder/src/lib.rs#L19)): - list presets provided by given runtime (`list-presets`), - display preset or default config provided by the runtime (`display-preset`), - build chain-spec using named preset (`create ... named-preset`), - The `ChainSpecBuilder` is extended with [`with_genesis_config_preset_name`](https://github.com/paritytech/polkadot-sdk/blob/3b41d66b/substrate/client/chain-spec/src/chain_spec.rs#L447) method which allows to build chain-spec using named preset provided by the runtime. Sample usage on the node side [here](https://github.com/paritytech/polkadot-sdk/blob/2caffaae /polkadot/node/service/src/chain_spec.rs#L404). Implementation of #1984. fixes: #150 part of: #25 --------- Co-authored-by:Sebastian Kunert <[email protected]> Co-authored-by:
Kian Paimani <[email protected]> Co-authored-by:
Oliver Tale-Yazdi <[email protected]>
-
- Apr 03, 2024
-
-
Andrei Sandu authored
Remove `fetch_next_scheduled_on_core` in favor of new wrapper and methods for accessing it. --------- Signed-off-by: -
Andrei Sandu authored
fixes https://github.com/paritytech/polkadot-sdk/issues/3775 Additionally moves the claim queue fetch utilities into `subsystem-util`. TODO: - [x] fix tests - [x] add elastic scaling tests --------- Signed-off-by:
-
- Apr 02, 2024
-
-
Serban Iorga authored
Working towards migrating the `parity-bridges-common` repo inside `polkadot-sdk`. This PR upgrades some dependencies in order to align them with the versions used in `parity-bridges-common` Related to https://github.com/paritytech/parity-bridges-common/issues/2538
-
Adrian Catangiu authored
This outputs: ``` 2024-04-02 14:36:02.135 ERROR tokio-runtime-worker beefy: 🥩 for session starting at block 21990151 no BEEFY authority key found in store, you must generate valid session keys (https://wiki.polkadot.network/docs/maintain-guides-how-to-validate-polkadot#generating-the-session-keys) ``` error log entry, once every session, for nodes running with `Role::Authority` that have no public BEEFY key in their keystore --------- Co-authored-by:
-
- Apr 01, 2024
-
-
s0me0ne-unkn0wn authored
Rejoice! Rejoice! The story is nearly over. This PR removes stale migrations, auxiliary structures, and package dependencies, thus making Rococo and Westend totally free from any `im-online`-related stuff. `im-online` still stays a part of the Substrate node and its runtime: https://github.com/paritytech/polkadot-sdk/blob/0d932484/substrate/bin/node/runtime/src/lib.rs#L2276-L2277 I'm not sure if it makes sense to remove it from there considering that we're not removing `im-online` from FRAME. Please share your opinion.
-
Alexandru Gheorghe authored
Runtime release 1.2 includes bumping of the ParachainHost APIs up to v10, so let's move all the released APIs out of vstaging folder, this PR does not include any logic changes only renaming of the modules and some moving around. Signed-off-by: -
Alexandru Gheorghe authored
The metric records the current protocol_version of the validator that just connected with the peer_map.len(), which contains all peers that connected, that has the effect the metric will be wrong since it won't tell us how many peers we have connected per version because it will always record the total number of peers Fix this by counting by version inside peer_map, additionally because that might be a bit heavier than len(), publish it only on-active leaves. --------- Signed-off-by:
-
- Mar 31, 2024
-
-
Bastian Köcher authored
Closes: https://github.com/paritytech/polkadot-sdk/issues/3906
-
- Mar 29, 2024
-
-
Andrei Sandu authored
Somehow https://github.com/paritytech/polkadot-sdk/pull/3795 was merged but tests are failing now on master. I suspect that CI is not even running these tests anymore which is a big issue. --------- Signed-off-by:
-
- Mar 28, 2024
-
-
Alin Dima authored
-
- Mar 27, 2024
-
-
Andrei Sandu authored
This works only for collators that implement the `collator_fn` allowing `collation-generation` subsystem to pull collations triggered on new heads. Also enables `request_v2::CollationFetchingResponse::CollationWithParentHeadData` for test adder/undying collators. TODO: - [x] fix tests - [x] new tests - [x] PR doc --------- Signed-off-by: -
Andrei Sandu authored
This is a long due chore ... --------- Signed-off-by:
ordian <[email protected]>
-
- Mar 26, 2024
-
-
ordian authored
Fixes #3826. The docs on the `candidates` field of `BlockEntry` were incorrectly stating that they are sorted by core index. The (incorrect) optimization was introduced in #3747 based on this assumption. The actual ordering is based on `CandidateIncluded` events ordering in the runtime. We revert this optimization here. - [x] verify the underlying issue - [x] add a regression test --------- Co-authored-by: -
Pavel Orlov authored
The PR provides API for obtaining: - the weight required to execute an XCM message, - a list of acceptable `AssetId`s for message execution payment, - the cost of the weight in the specified acceptable `AssetId`. It is meant to address an issue where one has to guess how much fee to pay for execution. Also, at the moment, a client has to guess which assets are acceptable for fee execution payment. See the related issue https://github.com/paritytech/polkadot-sdk/issues/690. With this API, a client is supposed to query the list of the supported asset IDs (in the XCM version format the client understands), weigh the XCM program the client wants to execute and convert the weight into one of the acceptable assets. Note that the client is supposed to know what program will be executed on what chains. However, having a small companion JS library for the pallet-xcm and xtokens should be enough to determine what XCM programs will be executed and where (since these pallets compose a known small set of programs). ```Rust pub trait XcmPaymentApi<Call> where Call: Codec, { /// Returns a list of acceptable payment assets. /// /// # Arguments /// /// * `xcm_version`: Version. fn query_acceptable_payment_assets(xcm_version: Version) -> Result<Vec<VersionedAssetId>, Error>; /// Returns a weight needed to execute a XCM. /// /// # Arguments /// /// * `message`: `VersionedXcm`. fn query_xcm_weight(message: VersionedXcm<Call>) -> Result<Weight, Error>; /// Converts a weight into a fee for the specified `AssetId`. /// /// # Arguments /// /// * `weight`: convertible `Weight`. /// * `asset`: `VersionedAssetId`. fn query_weight_to_asset_fee(weight: Weight, asset: VersionedAssetId) -> Result<u128, Error>; /// Get delivery fees for sending a specific `message` to a `destination`. /// These always come in a specific asset, defined by the chain. /// /// # Arguments /// * `message`: The message that'll be sent, necessary because most delivery fees are based on the /// size of the message. /// * `destination`: The destination to send the message to. Different destinations may use /// different senders that charge different fees. fn query_delivery_fees(destination: VersionedLocation, message: VersionedXcm<()>) -> Result<VersionedAssets, Error>; } ``` An [example](https://gist.github.com/PraetorP/4bc323ff85401abe253897ba990ec29d) of a client side code. --------- Co-authored-by:Francisco Aguirre <[email protected]> Co-authored-by:
Adrian Catangiu <[email protected]> Co-authored-by:
Daniel Shiposha <[email protected]>
-
Andrei Eres authored
Here we add the ability to save subsystem benchmark results in JSON format to display them as graphs To draw graphs, CI team will use [github-action-benchmark](https://github.com/benchmark-action/github-action-benchmark). Since we are using custom benchmarks, we need to prepare [a specific data type](https://github.com/benchmark-action/github-action-benchmark?tab=readme-ov-file#examples): ``` [ { "name": "CPU Load", "unit": "Percent", "value": 50 } ] ``` Then we'll get graphs like this: 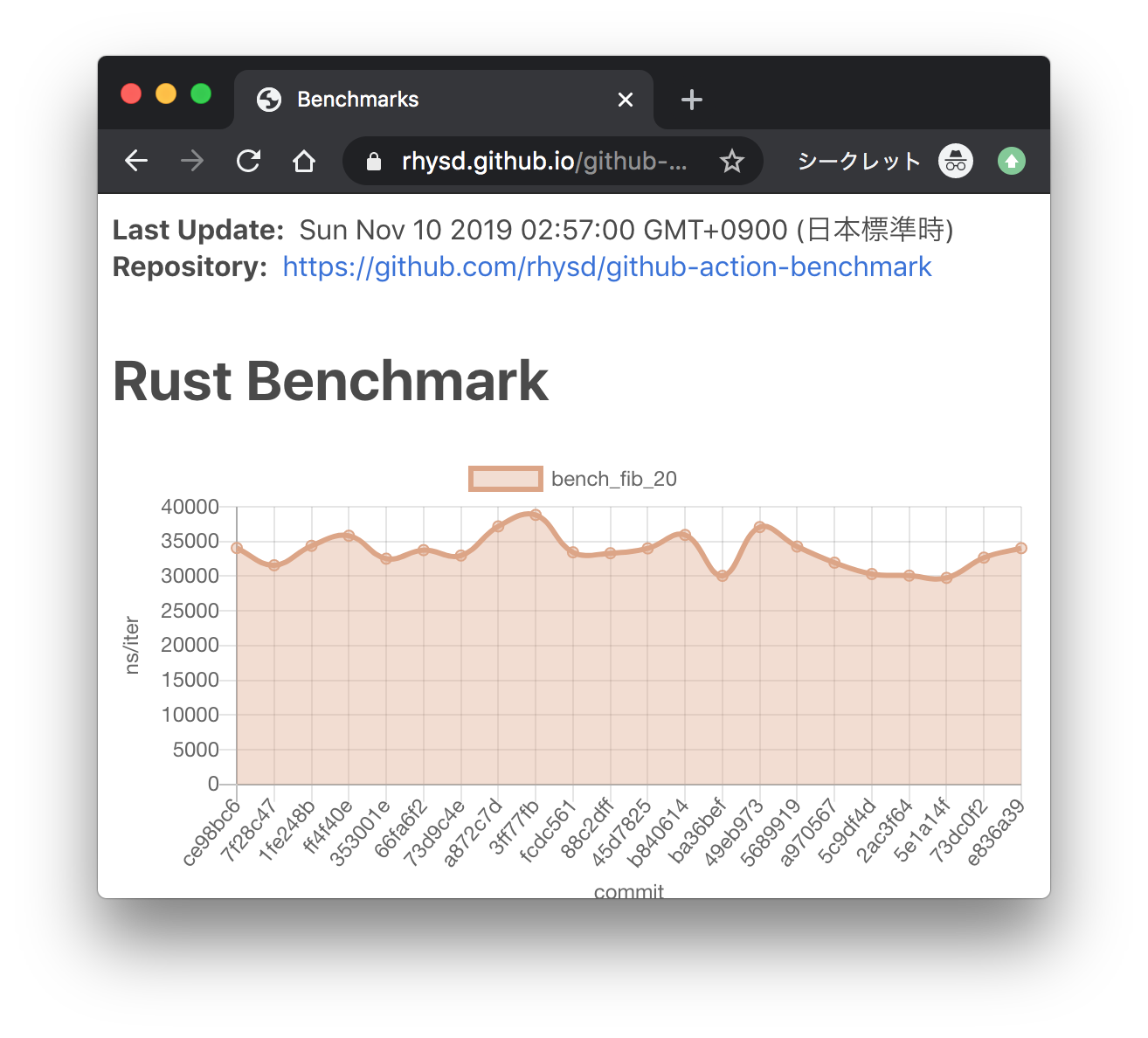 [A live page with graphs](https://benchmark-action.github.io/github-action-benchmark/dev/bench/) --------- Co-authored-by: -
Dcompoze authored
**Update:** Pushed additional changes based on the review comments. **This pull request fixes various spelling mistakes in this repository.** Most of the changes are contained in the first **3** commits: - `Fix spelling mistakes in comments and docs` - `Fix spelling mistakes in test names` - `Fix spelling mistakes in error messages, panic messages, logs and tracing` Other source code spelling mistakes are separated into individual commits for easier reviewing: - `Fix the spelling of 'authority'` - `Fix the spelling of 'REASONABLE_HEADERS_IN_JUSTIFICATION_ANCESTRY'` - `Fix the spelling of 'prev_enqueud_messages'` - `Fix the spelling of 'endpoint'` - `Fix the spelling of 'children'` - `Fix the spelling of 'PenpalSiblingSovereignAccount'` - `Fix the spelling of 'PenpalSudoAccount'` - `Fix the spelling of 'insufficient'` - `Fix the spelling of 'PalletXcmExtrinsicsBenchmark'` - `Fix the spelling of 'subtracted'` - `Fix the spelling of 'CandidatePendingAvailability'` - `Fix the spelling of 'exclusive'` - `Fix the spelling of 'until'` - `Fix the spelling of 'discriminator'` - `Fix the spelling of 'nonexistent'` - `Fix the spelling of 'subsystem'` - `Fix the spelling of 'indices'` - `Fix the spelling of 'committed'` - `Fix the spelling of 'topology'` - `Fix the spelling of 'response'` - `Fix the spelling of 'beneficiary'` - `Fix the spelling of 'formatted'` - `Fix the spelling of 'UNKNOWN_PROOF_REQUEST'` - `Fix the spelling of 'succeeded'` - `Fix the spelling of 'reopened'` - `Fix the spelling of 'proposer'` - `Fix the spelling of 'InstantiationNonce'` - `Fix the spelling of 'depositor'` - `Fix the spelling of 'expiration'` - `Fix the spelling of 'phantom'` - `Fix the spelling of 'AggregatedKeyValue'` - `Fix the spelling of 'randomness'` - `Fix the spelling of 'defendant'` - `Fix the spelling of 'AquaticMammal'` - `Fix the spelling of 'transactions'` - `Fix the spelling of 'PassingTracingSubscriber'` - `Fix the spelling of 'TxSignaturePayload'` - `Fix the spelling of 'versioning'` - `Fix the spelling of 'descendant'` - `Fix the spelling of 'overridden'` - `Fix the spelling of 'network'` Let me know if this structure is adequate. **Note:** The usage of the words `Merkle`, `Merkelize`, `Merklization`, `Merkelization`, `Merkleization`, is somewhat inconsistent but I left it as it is. ~~**Note:** In some places the term `Receival` is used to refer to message reception, IMO `Reception` is the correct word here, but I left it as it is.~~ ~~**Note:** In some places the term `Overlayed` is used instead of the more acceptable version `Overlaid` but I also left it as it is.~~ ~~**Note:** In some places the term `Applyable` is used instead of the correct version `Applicable` but I also left it as it is.~~ **Note:** Some usage of British vs American english e.g. `judgement` vs `judgment`, `initialise` vs `initialize`, `optimise` vs `optimize` etc. are both present in different places, but I suppose that's understandable given the number of contributors. ~~**Note:** There is a spelling mistake in `.github/CODEOWNERS` but it triggers errors in CI when I make changes to it, so I left it as it is.~~
-




















