Select Git revision
Search by author
- Any Author
- authors
-
Aaro Altonen altonen
-
 Administrator
Admin0
Administrator
Admin0
-
 Alexander
alvicsam
Alexander
alvicsam
-
Alexander Kalankhodzhaev kalaninja
-
Alexander Theißen athei
-
Alexandra a13xndra
-
Alin Dima alindima
-
Andrew Jones ascjones
-
André Silva andresilva
-
 Anthony Lazam
lazam
Anthony Lazam
lazam
-
Anton melekes
-
Anton Vilhelm Ásgeirsson antonva
-
 Arsham Teymouri
ArshamTeymouri
Arsham Teymouri
ArshamTeymouri
-
 Artyom Bakhtin
bakhtin
Artyom Bakhtin
bakhtin
-
Bernardo A. Rodrigues bernardoaraujor
-
Bradley Olson BradleyOlson64
-
Branislav Kontur bkontur
-
Bulat Saifullin BulatSaif
-
Chevdor chevdor
-
Chris Kerr piffle-rack
- Feb 14, 2025
-
-
Alexander Theißen authored
Partly addresses https://github.com/paritytech/polkadot-sdk/issues/6157 The benchmarks measuring the impact of contract sizes on calling or instantiating a contract were bogus because they needed to be written in assembly in order to tightly control the basic block size. This fixes the benchmarks for: - call_with_code_per_byte - upload_code - instantiate_with_code And adds a new benchmark that accounts for the fact that the interpreter will always compile whole basic blocks: - basic_block_compilation After this PR only the weight we assign to instructions need to be addressed. --------- Co-authored-by:
cmd[bot] <41898282+github-actions[bot]@users.noreply.github.com> Co-authored-by:
PG Herveou <pgherveou@gmail.com>
-
Alexandru Vasile authored
This PR implements conformance tests between our network backends (litep2p and libp2p). The PR creates a setup for extending testing in the future, while implementing the following tests: - connectivity check: Connect litep2p -> libp2p and libp2p -> litep2p - request response check: Send 32 requests from one backend to the other - notification check: Send 128 ping pong notifications and 128 from one backend to the other cc @paritytech/networking --------- Signed-off-by:Alexandru Vasile <alexandru.vasile@parity.io>
-
- Feb 13, 2025
-
-
PG Herveou authored
Cargo.lock change to subxt were rolled back Fixing it and updating it in Cargo.toml so it does not happen again --------- Co-authored-by:
-
- Feb 12, 2025
-
-
Serban Iorga authored
Related to https://github.com/paritytech/polkadot-sdk/issues/7360 Update some dependencies needed for implementing `DecodeWithMemTracking`: `parity-scale-codec` -> 3.7.4 `finality-grandpa` -> 0.16.3 `bounded-collections` -> 0.2.3 `impl-codec` -> 0.7.1
-
ordian authored
to zombienet-sdk 0.2.24 (also needed to update to this version for slashing to work). --------- Signed-off-by:
Alexandru Vasile <60601340+lexnv@users.noreply.github.com>
-
PG Herveou authored
Add debug endpoint to eth-rpc for capturing a block or a single transaction traces See: - PR #7166 --------- Co-authored-by:
Alexander Theißen <alex.theissen@me.com> Co-authored-by: command-bot <> Co-authored-by:
 Yuri Volkov <0@mcornholio.ru>
Co-authored-by:
Yuri Volkov <0@mcornholio.ru>
Co-authored-by: Maksym H <1177472+mordamax@users.noreply.github.com> Co-authored-by:
Santi Balaguer <santiago.balaguer@gmail.com> Co-authored-by:
Dónal Murray <donal.murray@parity.io> Co-authored-by:
xermicus <cyrill@parity.io>
-
- Feb 10, 2025
-
-
PG Herveou authored
Add support for eth_get_logs rpc method --------- Co-authored-by:
-
- Feb 07, 2025
-
-
PG Herveou authored
- Fix a deadlock on the RWLock cache - Remove eth-indexer, we won't need it anymore, the indexing will be started from within eth-rpc directly --------- Co-authored-by:
-
- Feb 05, 2025
-
-
Iulian Barbu authored
# Description Copy pasted the `parachain-template-node` offchain worker setup to omni-node-lib for both aura and manual seal nodes. Closes #7447 ## Integration Enabled offchain workers for both `polkadot-omni-node` and `polkadot-parachain` nodes. This would allow executing offchain logic in the runtime and considering it on the node side. --------- Signed-off-by:
Iulian Barbu <iulian.barbu@parity.io> Co-authored-by:
-
- Feb 04, 2025
-
-
Alexander Theißen authored
This PR is centered around a main fix regarding the base deposit and a bunch of drive by or related fixtures that make sense to resolve in one go. It could be broken down more but I am constantly rebasing this PR and would appreciate getting those fixes in as-one. **This adds a multi block migration to Westend AssetHub that wipes the pallet state clean. This is necessary because of the changes to the `ContractInfo` storage item. It will not delete the child storage though. This will leave a tiny bit of garbage behind but won't cause any problems. They will just be orphaned.** ## Record the deposit for immutable data into the `storage_base_deposit` The `storage_base_deposit` are all the deposit a contract has to pay for existing. It included the deposit for its own metadata and a deposit proportional (< 1.0x) to the size of its code. However, the immutable code size was not recorded there. This would lead to the situation where on terminate this portion wouldn't be refunded staying locked into the contract. It would also make the calculation of the deposit changes on `set_code_hash` more complicated when it updates the immutable data (to be done in #6985). Reason is because it didn't know how much was payed before since the storage prices could have changed in the mean time. In order for this solution to work I needed to delay the deposit calculation for a new contract for after the contract is done executing is constructor as only then we know the immutable data size. Before, we just charged this eagerly in `charge_instantiate` before we execute the constructor. Now, we merely send the ED as free balance before the constructor in order to create the account. After the constructor is done we calculate the contract base deposit and charge it. This will make `set_code_hash` much easier to implement. As a side effect it is now legal to call `set_immutable_data` multiple times per constructor (even though I see no reason to do so). It simply overrides the immutable data with the new value. The deposit accounting will be done after the constructor returns (as mentioned above) instead of when setting the immutable data. ## Don't pre-charge for reading immutable data I noticed that we were pre-charging weight for the max allowable immutable data when reading those values and then refunding after read. This is not necessary as we know its length without reading the storage as we store it out of band in contract metadata. This makes reading it free. Less pre-charging less problems. ## Remove delegate locking Fixes #7092 This is also in the spirit of making #6985 easier to implement. The locking complicates `set_code_hash` as we might need to block settings the code hash when locks exist. Check #7092 for further rationale. ## Enforce "no terminate in constructor" eagerly We used to enforce this rule after the contract execution returned. Now we error out early in the host call. This makes it easier to be sure to argue that a contract info still exists (wasn't terminated) when a constructor successfully returns. All around this his just much simpler than dealing this check. ## Moved refcount functions to `CodeInfo` They never really made sense to exist on `Stack`. But now with the locking gone this makes even less sense. The refcount is stored inside `CodeInfo` to lets just move them there. ## Set `CodeHashLockupDepositPercent` for test runtime The test runtime was setting `CodeHashLockupDepositPercent` to zero. This was trivializing many code paths and excluded them from testing. I set it to `30%` which is our default value and fixed up all the tests that broke. This should give us confidence that the lockup doeposit collections properly works. ## Reworked the `MockExecutable` to have both a `deploy` and a `call` entry point This type used for testing could only have either entry points but not both. In order to fix the `immutable_data_set_overrides` I needed to a new function `add_both` to `MockExecutable` that allows to have both entry points. Make sure to make use of it in the future :) --------- Co-authored-by: command-bot <> Co-authored-by:
Bastian Köcher <git@kchr.de> Co-authored-by:
Oliver Tale-Yazdi <oliver.tale-yazdi@parity.io>
-
- Jan 30, 2025
-
-
Stephane Gurgenidze authored
malus-collator: implement malicious collator submitting same collation to all backing groups (#6924) ## Issues - [[#5049] Elastic scaling: zombienet tests](https://github.com/paritytech/polkadot-sdk/issues/5049) - [[#4526] Add zombienet tests for malicious collators](https://github.com/paritytech/polkadot-sdk/issues/4526) ## Description Modified the undying collator to include a malus mode, in which it submits the same collation to all assigned backing groups. ## TODO * [X] Implement malicious collator that submits the same collation to all backing groups; * [X] Avoid the core index check in the collation generation subsystem: https://github.com/paritytech/polkadot-sdk/blob/master/polkadot/node/collation-generation/src/lib.rs#L552-L553; * [X] Resolve the mismatch between the descriptor and the commitments core index: https://github.com/paritytech/polkadot-sdk/pull/7104 * [X] Implement `duplicate_collations` test with zombienet-sdk; * [X] Add PRdoc.
-
dharjeezy authored
This PR modifies the fatxpool to use tracing instead of log for logging. closes #5490 Polkadot address: 12GyGD3QhT4i2JJpNzvMf96sxxBLWymz4RdGCxRH5Rj5agKW --------- Co-authored-by:Michal Kucharczyk <1728078+michalkucharczyk@users.noreply.github.com>
-
Jeeyong Um authored
# Description Close #7122. This PR replaces the unmaintained `derivative` dependency with `derive-where`. ## Integration This PR doesn't change the public interfaces. ## Review Notes The `derivative` crate, previously used to derive basic traits for structs with generics or enums, is no longer actively maintained. It has been replaced with the `derive-where` crate, which offers a more straightforward syntax while providing the same features as `derivative`. --------- Co-authored-by:Guillaume Thiolliere <gui.thiolliere@gmail.com>
-
- Jan 29, 2025
-
-
Branislav Kontur authored
This PR contains small fixes and backwards compatibility issues identified during work on the larger PR: https://github.com/paritytech/polkadot-sdk/issues/6906. --------- Co-authored-by: -
xermicus authored
This PR implements the block author API method. Runtimes ought to implement it such that it corresponds to the `coinbase` EVM opcode. --------- Signed-off-by:
Cyrill Leutwiler <bigcyrill@hotmail.com> Co-authored-by: command-bot <> Co-authored-by:
-
- Jan 28, 2025
-
-
 Andrew Jones authored
Andrew Jones authoredCloses #216. This PR allows pallets to define a `view_functions` impl like so: ```rust #[pallet::view_functions] impl<T: Config> Pallet<T> where T::AccountId: From<SomeType1> + SomeAssociation1, { /// Query value no args. pub fn get_value() -> Option<u32> { SomeValue::<T>::get() } /// Query value with args. pub fn get_value_with_arg(key: u32) -> Option<u32> { SomeMap::<T>::get(key) } } ``` ### `QueryId` Each view function is uniquely identified by a `QueryId`, which for this implementation is generated by: ```twox_128(pallet_name) ++ twox_128("fn_name(fnarg_types) -> return_ty")``` The prefix `twox_128(pallet_name)` is the same as the storage prefix for pallets and take into account multiple instances of the same pallet. The suffix is generated from the fn type signature so is guaranteed to be unique for that pallet impl. For one of the view fns in the example above it would be `twox_128("get_value_with_arg(u32) -> Option<u32>")`. It is a known limitation that only the type names themselves are taken into account: in the case of type aliases the signature may have the same underlying types but a different id; for generics the concrete types may be different but the signatures will remain the same. The existing Runtime `Call` dispatchables are addressed by their concatenated indices `pallet_index ++ call_index`, and the dispatching is handled by the SCALE decoding of the `RuntimeCallEnum::PalletVariant(PalletCallEnum::dispatchable_variant(payload))`. For `view_functions` the runtime/pallet generated enum structure is replaced by implementing the `DispatchQuery` trait on the outer (runtime) scope, dispatching to a pallet based on the id prefix, and the inner (pallet) scope dispatching to the specific function based on the id suffix. Future implementations could also modify/extend this scheme and routing to pallet agnostic queries. ### Executing externally These view functions can be executed externally via the system runtime api: ```rust pub trait ViewFunctionsApi<QueryId, Query, QueryResult, Error> where QueryId: codec::Codec, Query: codec::Codec, QueryResult: codec::Codec, Error: codec::Codec, { /// Execute a view function query. fn execute_query(query_id: QueryId, query: Query) -> Result<QueryResult, Error>; } ``` ### `XCQ` Currently there is work going on by @xlc to implement [`XCQ`](https://github.com/open-web3-stack/XCQ/) which may eventually supersede this work. It may be that we still need the fixed function local query dispatching in addition to XCQ, in the same way that we have chain specific runtime dispatchables and XCM. I have kept this in mind and the high level query API is agnostic to the underlying query dispatch and execution. I am just providing the implementation for the `view_function` definition. ### Metadata Currently I am utilizing the `custom` section of the frame metadata, to avoid modifying the official metadata format until this is standardized. ### vs `runtime_api` There are similarities with `runtime_apis`, some differences being: - queries can be defined directly on pallets, so no need for boilerplate declarations and implementations - no versioning, the `QueryId` will change if the signature changes. - possibility for queries to be executed from smart contracts (see below) ### Calling from contracts Future work would be to add `weight` annotations to the view function queries, and a host function to `pallet_contracts` to allow executing these queries from contracts. ### TODO - [x] Consistent naming (view functions pallet impl, queries, high level api?) - [ ] End to end tests via `runtime_api` - [ ] UI tests - [x] Mertadata tests - [ ] Docs --------- Co-authored-by:kianenigma <kian@parity.io> Co-authored-by:
James Wilson <james@jsdw.me> Co-authored-by:
Giuseppe Re <giuseppe.re@parity.io> Co-authored-by:
Guillaume Thiolliere <guillaume.thiolliere@parity.io>
-
- Jan 27, 2025
-
-
Ron authored
Resolves (partially): https://github.com/paritytech/polkadot-sdk/issues/7148 (see _Problem 1 - `ShouldExecute` tuple implementation and `Deny` filter tuple_) This PR changes the behavior of `DenyThenTry` from the pattern `DenyIfAllMatch` to `DenyIfAnyMatch` for the tuple. I would expect the latter is the right behavior so make the fix in place, but we can also add a dedicated Impl with the legacy one untouched. ## TODO - [x] add unit-test for `DenyReserveTransferToRelayChain` - [x] add test and investigate/check `DenyThenTry` as discussed [here](https://github.com/paritytech/polkadot-sdk/pull/6838#discussion_r1914553990) and update documentation if needed --------- Co-authored-by:
Branislav Kontur <bkontur@gmail.com> Co-authored-by:
Francisco Aguirre <franciscoaguirreperez@gmail.com> Co-authored-by: command-bot <> Co-authored-by:
Clara van Staden <claravanstaden64@gmail.com> Co-authored-by:
Adrian Catangiu <adrian@parity.io>
-
- Jan 26, 2025
-
-
Branislav Kontur authored
Part of: https://github.com/paritytech/polkadot-sdk/issues/6906
-
- Jan 24, 2025
-
-
PG Herveou authored
- Add option to specify database_url using DATABASE_URL environment variable - Add a eth-rpc-tester rust bin that can be used to test deployment before releasing eth-rpc - make evm_block non fallible so that it can return an Ok response for older blocks when the runtime API is not available - update cargo.lock to integrate changes from https://github.com/paritytech/subxt/pull/1904 --------- Co-authored-by: -
Branislav Kontur authored
Closes: https://github.com/paritytech/polkadot-sdk/issues/2904 --------- Co-authored-by: command-bot <>
-
- Jan 23, 2025
-
-
Branislav Kontur authored
This PR contains small fixes identified during work on the larger PR: https://github.com/paritytech/polkadot-sdk/issues/6906. --------- Co-authored-by: command-bot <>
-
- Jan 22, 2025
-
-
FereMouSiopi authored
Part of https://github.com/paritytech/polkadot-sdk/issues/6504 --------- Co-authored-by: command-bot <> Co-authored-by: -
Serban Iorga authored
Related to https://github.com/paritytech/polkadot-sdk/issues/4523 Follow-up for: https://github.com/paritytech/polkadot-sdk/pull/5188 Reopening https://github.com/paritytech/polkadot-sdk/pull/6732 as a new PR --------- Co-authored-by: command-bot <>
-
- Jan 21, 2025
-
-
Ludovic_Domingues authored
Part of #6504 --------- Co-authored-by:
-
- Jan 20, 2025
-
-
runcomet authored
Part of https://github.com/paritytech/polkadot-sdk/issues/6504 ### Added modules - `utility`: Traits not tied to any direct operation in the runtime. polkadot address: 14SRqZTC1d8rfxL8W1tBTnfUBPU23ACFVPzp61FyGf4ftUFg --------- Co-authored-by: -
Ron authored
Part of https://github.com/paritytech/polkadot-sdk/issues/6504
-
seemantaggarwal authored
Use docify export for parachain template hardcoded configuration and embed it in its README #6333 (#7093) Use docify export for parachain template hardcoded configuration and embed it in its README #6333 Docify currently has a limitation of not being able to embed a variable/const in its code, without embedding it's definition, even if do something in a string like "this is a sample string ${sample_variable}" It will embed the entire string "this is a sample string ${sample_variable}" without replacing the value of sample_variable from the code Hence, the goal was just to make it obvious in the README where the PARACHAIN_ID value is coming from, so a note has been added at the start for the same, so whenever somebody is running these commands, they will be aware about the value and replace accordingly. To make it simpler, we added a rust ignore block so the user can just look it up in the readme itself and does not have to scan through the runtime directory for the value. --------- Co-authored-by:Iulian Barbu <14218860+iulianbarbu@users.noreply.github.com>
-
Sebastian Kunert authored
Follow-up to #6825, which introduced this bug. We use the `can_build_upon` method to ask the runtime if it is fine to build another block. The runtime checks this based on the [`ConsensusHook`](https://github.com/paritytech/polkadot-sdk/blob/c1b7c302/cumulus/pallets/aura-ext/src/consensus_hook.rs#L110-L110) implementation, the most popular one being the `FixedConsensusHook`. In #6825 I removed a check that would always allow us to build when we are building on an included block. Turns out this check is still required when: 1. The [`UnincludedSegment` ](https://github.com/paritytech/polkadot-sdk/blob/c1b7c302 /cumulus/pallets/parachain-system/src/lib.rs#L758-L758) storage item in pallet-parachain-system is equal or larger than the unincluded segment. 2. We are calling the `can_build_upon` runtime API where the included block has progressed offchain to the current parent block (so last entry in the `UnincludedSegment` storage item). In this scenario the last entry in `UnincludedSegment` does not have a hash assigned yet (because it was not available in `on_finalize` of the previous block). So the unincluded segment will be reported at its maximum length which will forbid building another block. Ideally we would have a more elegant solution than to rely on the node-side here. But for now the check is reintroduced and a test is added to not break it again by accident. --------- Co-authored-by: command-bot <> Co-authored-by:
-
- Jan 17, 2025
-
-
PG Herveou authored
Add foundation for supporting call traces in pallet_revive Follow up: - PR #7167 Add changes to eth-rpc to introduce debug endpoint that will use pallet-revive tracing features - PR #6727 Add new RPC to the client and implement tracing runtime API that can capture traces on previous blocks --------- Co-authored-by: -
Alexander Theißen authored
Update to PolkaVM `0.19`. This version renumbers the opcodes in order to be in-line with the grey paper. Hopefully, for the last time. This means that it breaks existing contracts. --------- Signed-off-by:
-
- Jan 16, 2025
-
-
Ankan authored
Migrate staking currency from `traits::LockableCurrency` to `traits::fungible::holds`. Resolves part of https://github.com/paritytech/polkadot-sdk/issues/226. ## Changes ### Nomination Pool TransferStake is now incompatible with fungible migration as old pools were not meant to have additional ED. Since they are anyways deprecated, removed its usage from all test runtimes. ### Staking - Config: `Currency` becomes of type `Fungible` while `OldCurrency` is the `LockableCurrency` used before. - Lazy migration of accounts. Any ledger update will create a new hold with no extra reads/writes. A permissionless extrinsic `migrate_currency()` releases the old `lock` along with some housekeeping. - Staking now requires ED to be left free. It also adds no consumer to staking accounts. - If hold cannot be applied to all stake, the un-holdable part is force withdrawn from the ledger. ### Delegated Staking The pallet does not add provider for agents anymore. ## Migration stats ### Polkadot Total accounts that can be migrated: 59564 Accounts failing to migrate: 0 Accounts with stake force withdrawn greater than ED: 59 Total force withdrawal: 29591.26 DOT ### Kusama Total accounts that can be migrated: 26311 Accounts failing to migrate: 0 Accounts with stake force withdrawn greater than ED: 48 Total force withdrawal: 1036.05 KSM [Full logs here](https://hackmd.io/@ak0n/BklDuFra0). ## Note about locks (freeze) vs holds With locks or freezes, staking could use total balance of an account. But with holds, the account needs to be left with at least Existential Deposit in free balance. This would also affect nomination pools which till now has been able to stake all funds contributed to it. An alternate version of this PR is https://github.com/paritytech/polkadot-sdk/pull/5658 where staking pallet does not add any provider, but means pools and delegated-staking pallet has to provide for these accounts and makes the end to end logic (of provider and consumer ref) lot less intuitive and prone to bug. This PR now introduces requirement for stakers to maintain ED in their free balance. This helps with removing the bug prone incrementing and decrementing of consumers and providers. ## TODO - [x] Test: Vesting + governance locked funds can be staked. - [ ] can `Call::restore_ledger` be removed? @gpestana - [x] Ensure unclaimed withdrawals is not affected by no provider for pool accounts. - [x] Investigate kusama accounts with balance between 0 and ED. - [x] Permissionless call to release lock. - [x] Migration of consumer (dec) and provider (inc) for direct stakers. - [x] force unstake if hold cannot be applied to all stake. - [x] Fix try state checks (it thinks nothing is staked for unmigrated ledgers). - [x] Bench `migrate_currency`. - [x] Virtual Staker migration test. - [x] Ensure total issuance is upto date when minting rewards. ## Followup - https://github.com/paritytech/polkadot-sdk/issues/5742 --------- Co-authored-by: command-bot <>
-
Liam Aharon authored
Closes #3149 ## Description This PR introduces `pallet-asset-rewards`, which allows accounts to be rewarded for freezing `fungible` tokens. The motivation for creating this pallet is to allow incentivising LPs. See the pallet docs for more info about the pallet. ## Runtime changes The pallet has been added to - `asset-hub-rococo` - `asset-hub-westend` The `NativeAndAssets` `fungibles` Union did not contain `PoolAssets`, so it has been renamed `NativeAndNonPoolAssets` A new `fungibles` Union `NativeAndAllAssets` was created to encompass all assets and the native token. ## TODO - [x] Emulation tests - [x] Fill in Freeze logic (blocked https://github.com/paritytech/polkadot-sdk/issues/3342) and re-run benchmarks --------- Co-authored-by: command-bot <> Co-authored-by:
muharem <ismailov.m.h@gmail.com> Co-authored-by:
-
- Jan 15, 2025
-
-
Alexandru Vasile authored
This PR provides the partial results of the `GetRecord` kademlia query. This significantly improves the authority discovery records, from ~37 minutes to ~2/3 minutes. In contrast, libp2p discovers authority records in around ~10 minutes. The authority discovery was slow because litep2p provided the records only after the Kademlia query was completed. A normal Kademlia query completes in around 40 seconds to a few minutes. In this PR, partial records are provided as soon as they are discovered from the network. ### Testing Done Started a node in Kusama with `--validator` and litep2p backend. The node discovered 996/1000 authority records in ~ 1 minute 45 seconds. 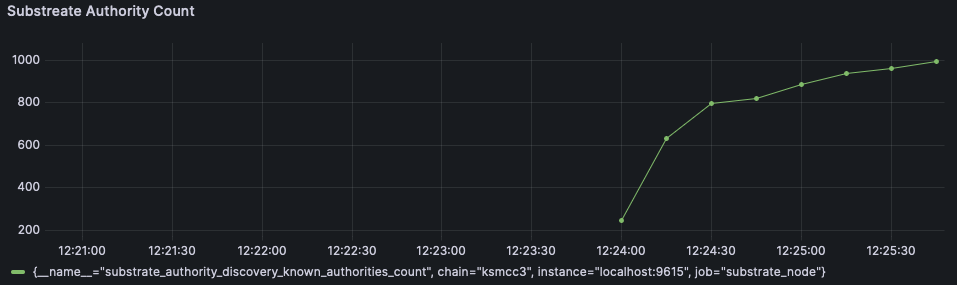 ### Before & After In this image, on the left side is libp2p, in the middle litep2p without this PR, on the right litep2p with this PR 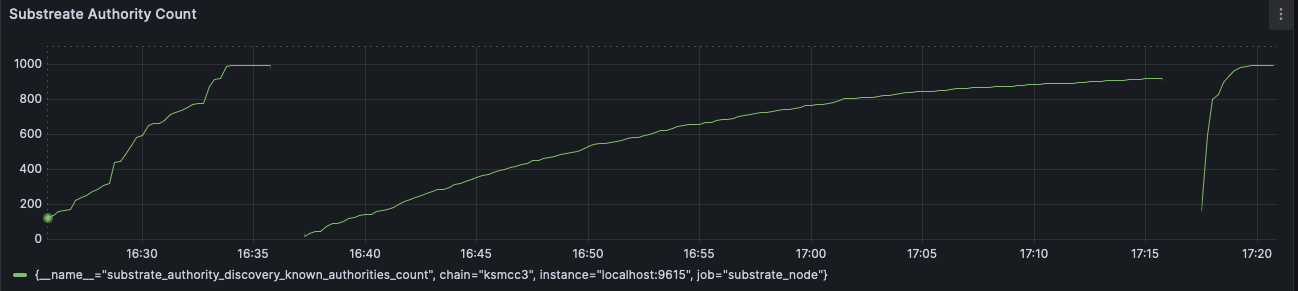 Closes: https://github.com/paritytech/polkadot-sdk/issues/7077 cc @paritytech/networking --------- Signed-off-by:
-
- Jan 14, 2025
-
-
Sebastian Kunert authored
closes #3967 ## Changes We now use relay chain slots to measure velocity on chain. Previously we were storing the current parachain slot. Then in `on_state_proof` of the `ConsensusHook` we were checking how many blocks were athored in the current parachain slot. This works well when the parachain slot time and relay chain slot time is the same. With elastic scaling, we can have parachain slot times lower than that of the relay chain. In these cases we want to measure velocity in relation to the relay chain. This PR adjusts that. ## Migration This PR includes a migration. Storage item `SlotInfo` of pallet `aura-ext` is renamed to `RelaySlotInfo` to better reflect its new content. A migration has been added that just kills the old storage item. `RelaySlotInfo` will be `None` initially but its value will be adjusted after one new relay chain slot arrives. --------- Co-authored-by: command-bot <> Co-authored-by: -
PG Herveou authored
Add an option to persist EVM transaction hash to a SQL db. This should make it possible to run a full archive ETH RPC node (assuming the substrate node is also a full archive node) Some queries such as eth_getTransactionByHash, eth_getBlockTransactionCountByHash, and other need to work with a transaction hash indexes, which are not stored in Substrate and need to be stored by the eth-rpc proxy. The refactoring break down the Client into a `BlockInfoProvider` and `ReceiptProvider` - BlockInfoProvider does not need any persistence data, as we can fetch all block info from the source substrate chain - ReceiptProvider comes in two flavor, - An in memory cache implementation - This is the one we had so far. - A DB implementation - This one persist rows with the block_hash, the transaction_index and the transaction_hash, so that we can later fetch the block and extrinsic for that receipt and reconstruct the ReceiptInfo object. This PR also adds ...
-
- Jan 13, 2025
-
-
Bastian Köcher authored
Closes: https://github.com/paritytech/polkadot-sdk/issues/7033
-
- Jan 09, 2025
-
-
seemantaggarwal authored
# Description Migrating salary pallet to use umbrella crate. It is a follow-up from https://github.com/paritytech/polkadot-sdk/pull/7025 Why did I create this new branch? I did this, so that the unnecessary cargo fmt changes from the previous branch are discarded and hence opened this new PR. ## Review Notes This PR migrates pallet-salary to use the umbrella crate. Added change: Explanation requested for why `TestExternalities` was replaced by `TestState` as testing_prelude already includes it `pub use sp_io::TestExternalities as TestState;` I have also modified the defensive! macro to be compatible with umbrella crate as it was being used in the salary pallet
-
- Jan 07, 2025
-
-
Alin Dima authored
Will fix: https://github.com/paritytech/polkadot-sdk/issues/6574 https://github.com/paritytech/polkadot-sdk/issues/6644 https://github.com/paritytech/polkadot-sdk/issues/6062 --------- Co-authored-by:Javier Viola <javier@parity.io>
-
Utkarsh Bhardwaj authored
# Description Migrate pallet-node-authorization to use umbrella crate. Part of #6504 ## Review Notes * This PR migrates pallet-node-authorization to use the umbrella crate. * Some imports like below have not been added to any prelude as they have very limited usage across the various pallets. ```rust use sp_core::OpaquePeerId as PeerId; ``` * Added a commonly used runtime trait for testing in the `testing_prelude` in `substrate/frame/src/lib.rs`: ```rust pub use sp_runtime::traits::BadOrigin; ``` * `weights.rs` uses the `weights_prelude` like: ```rust use frame::weights_prelude::*; ``` * `tests.rs` and `mock.rs` use the `testing_prelude`: ```rust use frame::testing_prelude::*; ``` * `lib.rs` uses the main `prelude` like: ```rust use frame::prelude::*; ``` * For testing: Checked that local build works and tests run successfully.
-
Jeeyong Um authored
# Description This PR removes usage of deprecated `sp-std` from Substrate. (following PR of #5010) ## Integration This PR doesn't remove re-exported `sp_std` from any crates yet, so downstream projects using re-exported `sp_std` will not be affected. ## Review Notes The existing code using `sp-std` is refactored to use `alloc` and `core` directly. The key-value maps are instantiated from a vector of tuples directly instead of using `sp_std::map!` macro. `sp_std::Writer` is a helper type to use `Vec<u8>` with `core::fmt::Write` trait. This PR copied it into `sp-runtime`, because all crates using `sp_std::Writer` (including `sp-runtime` itself, `frame-support`, etc.) depend on `sp-runtime`. If this PR is merged, I would write following PRs to remove remaining usage of `sp-std` from `bridges` and `cumulus`. --------- Co-authored-by: command-bot <> Co-authored-by:
Bastian Köcher <info@kchr.de> Co-authored-by:
-




















