- Apr 25, 2024
-
-
Andrei Eres authored
Should help us to understand more what's happening between individual runs and possibly adjust the number of runs
-
- Apr 08, 2024
-
-
Aaro Altonen authored
[litep2p](https://github.com/altonen/litep2p) is a libp2p-compatible P2P networking library. It supports all of the features of `rust-libp2p` that are currently being utilized by Polkadot SDK. Compared to `rust-libp2p`, `litep2p` has a quite different architecture which is why the new `litep2p` network backend is only able to use a little of the existing code in `sc-network`. The design has been mainly influenced by how we'd wish to structure our networking-related code in Polkadot SDK: independent higher-levels protocols directly communicating with the network over links that support bidirectional backpressure. A good example would be `NotificationHandle`/`RequestResponseHandle` abstractions which allow, e.g., `SyncingEngine` to directly communicate with peers to announce/request blocks. I've tried running `polkadot --network-backend litep2p` with a few different peer configurations and there is a noticeable reduction in networking CPU usage. For high load (`--out-peers 200`), networking CPU usage goes down from ~110% to ~30% (80 pp) and for normal load (`--out-peers 40`), the usage goes down from ~55% to ~18% (37 pp). These should not be taken as final numbers because: a) there are still some low-hanging optimization fruits, such as enabling [receive window auto-tuning](https://github.com/libp2p/rust-yamux/pull/176 ), integrating `Peerset` more closely with `litep2p` or improving memory usage of the WebSocket transport b) fixing bugs/instabilities that incorrectly cause `litep2p` to do less work will increase the networking CPU usage c) verification in a more diverse set of tests/conditions is needed Nevertheless, these numbers should give an early estimate for CPU usage of the new networking backend. This PR consists of three separate changes: * introduce a generic `PeerId` (wrapper around `Multihash`) so that we don't have use `NetworkService::PeerId` in every part of the code that uses a `PeerId` * introduce `NetworkBackend` trait, implement it for the libp2p network stack and make Polkadot SDK generic over `NetworkBackend` * implement `NetworkBackend` for litep2p The new library should be considered experimental which is why `rust-libp2p` will remain as the default option for the time being. This PR currently depends on the master branch of `litep2p` but I'll cut a new release for the library once all review comments have been addresses. --------- Signed-off-by:
Alexandru Vasile <[email protected]> Co-authored-by:
Dmitry Markin <[email protected]> Co-authored-by:
Alexandru Vasile <[email protected]> Co-authored-by:
-
- Apr 02, 2024
-
-
Serban Iorga authored
Working towards migrating the `parity-bridges-common` repo inside `polkadot-sdk`. This PR upgrades some dependencies in order to align them with the versions used in `parity-bridges-common` Related to https://github.com/paritytech/parity-bridges-common/issues/2538
-
- Apr 01, 2024
-
-
Alexandru Gheorghe authored
Runtime release 1.2 includes bumping of the ParachainHost APIs up to v10, so let's move all the released APIs out of vstaging folder, this PR does not include any logic changes only renaming of the modules and some moving around. Signed-off-by:Alexandru Gheorghe <[email protected]>
-
- Mar 26, 2024
-
-
Andrei Eres authored
Here we add the ability to save subsystem benchmark results in JSON format to display them as graphs To draw graphs, CI team will use [github-action-benchmark](https://github.com/benchmark-action/github-action-benchmark). Since we are using custom benchmarks, we need to prepare [a specific data type](https://github.com/benchmark-action/github-action-benchmark?tab=readme-ov-file#examples): ``` [ { "name": "CPU Load", "unit": "Percent", "value": 50 } ] ``` Then we'll get graphs like this: 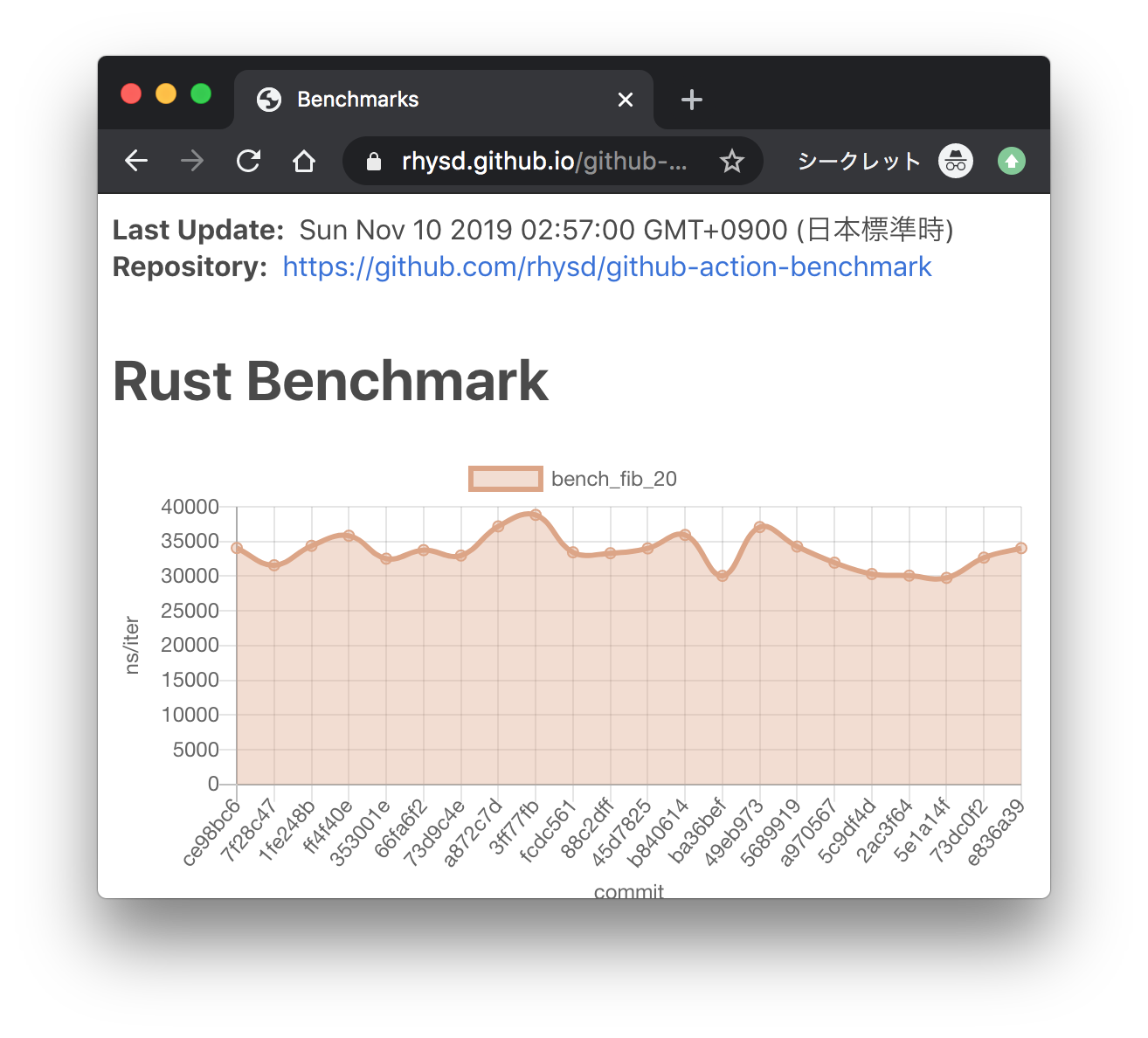 [A live page with graphs](https://benchmark-action.github.io/github-action-benchmark/dev/bench/ ) --------- Co-authored-by:
ordian <[email protected]>
-
Dcompoze authored
**Update:** Pushed additional changes based on the review comments. **This pull request fixes various spelling mistakes in this repository.** Most of the changes are contained in the first **3** commits: - `Fix spelling mistakes in comments and docs` - `Fix spelling mistakes in test names` - `Fix spelling mistakes in error messages, panic messages, logs and tracing` Other source code spelling mistakes are separated into individual commits for easier reviewing: - `Fix the spelling of 'authority'` - `Fix the spelling of 'REASONABLE_HEADERS_IN_JUSTIFICATION_ANCESTRY'` - `Fix the spelling of 'prev_enqueud_messages'` - `Fix the spelling of 'endpoint'` - `Fix the spelling of 'children'` - `Fix the spelling of 'PenpalSiblingSovereignAccount'` - `Fix the spelling of 'PenpalSudoAccount'` - `Fix the spelling of 'insufficient'` - `Fix the spelling of 'PalletXcmExtrinsicsBenchmark'` - `Fix the spelling of 'subtracted'` - `Fix the spelling of 'CandidatePendingAvailability'` - `Fix the spelling of 'exclusive'` - `Fix the spelling of 'until'` - `Fix the spelling of 'discriminator'` - `Fix the spelling of 'nonexistent'` - `Fix the spelling of 'subsystem'` - `Fix the spelling of 'indices'` - `Fix the spelling of 'committed'` - `Fix the spelling of 'topology'` - `Fix the spelling of 'response'` - `Fix the spelling of 'beneficiary'` - `Fix the spelling of 'formatted'` - `Fix the spelling of 'UNKNOWN_PROOF_REQUEST'` - `Fix the spelling of 'succeeded'` - `Fix the spelling of 'reopened'` - `Fix the spelling of 'proposer'` - `Fix the spelling of 'InstantiationNonce'` - `Fix the spelling of 'depositor'` - `Fix the spelling of 'expiration'` - `Fix the spelling of 'phantom'` - `Fix the spelling of 'AggregatedKeyValue'` - `Fix the spelling of 'randomness'` - `Fix the spelling of 'defendant'` - `Fix the spelling of 'AquaticMammal'` - `Fix the spelling of 'transactions'` - `Fix the spelling of 'PassingTracingSubscriber'` - `Fix the spelling of 'TxSignaturePayload'` - `Fix the spelling of 'versioning'` - `Fix the spelling of 'descendant'` - `Fix the spelling of 'overridden'` - `Fix the spelling of 'network'` Let me know if this structure is adequate. **Note:** The usage of the words `Merkle`, `Merkelize`, `Merklization`, `Merkelization`, `Merkleization`, is somewhat inconsistent but I left it as it is. ~~**Note:** In some places the term `Receival` is used to refer to message reception, IMO `Reception` is the correct word here, but I left it as it is.~~ ~~**Note:** In some places the term `Overlayed` is used instead of the more acceptable version `Overlaid` but I also left it as it is.~~ ~~**Note:** In some places the term `Applyable` is used instead of the correct version `Applicable` but I also left it as it is.~~ **Note:** Some usage of British vs American english e.g. `judgement` vs `judgment`, `initialise` vs `initialize`, `optimise` vs `optimize` etc. are both present in different places, but I suppose that's understandable given the number of contributors. ~~**Note:** There is a spelling mistake in `.github/CODEOWNERS` but it triggers errors in CI when I make changes to it, so I left it as it is.~~
-
Dcompoze authored
Fixes formatting for https://github.com/paritytech/polkadot-sdk/pull/3698
-
- Mar 25, 2024
-
-
Andrei Eres authored
Adds availability-write regression tests. The results for the `availability-distribution` subsystem are volatile, so I had to reduce the precision of the test.
-
- Mar 18, 2024
-
-
jokess123 authored
-
- Mar 17, 2024
-
-
dependabot[bot] authored
Bumps the known_good_semver group with 3 updates: [log](https://github.com/rust-lang/log), [syn](https://github.com/dtolnay/syn) and [clap](https://github.com/clap-rs/clap). Updates `log` from 0.4.20 to 0.4.21 <details> <summary>Changelog</summary> <p><em>Sourced from <a href="https://github.com/rust-lang/log/blob/master/CHANGELOG.md">log's changelog</a>.</em></p> <blockquote> <h2>[0.4.21] - 2024-02-27</h2> <h2>What's Changed</h2> <ul> <li>Minor clippy nits by <a href="https://github.com/nyurik"><code>@nyurik</code></a> in <a href="https://redirect.github.com/rust-lang/log/pull/578">rust-lang/log#578</a></li> <li>Simplify Display impl by <a href="https://github.com/nyurik"><code>@nyurik</code></a> in <a href="https://redirect.github.com/rust-lang/log/pull/579">rust-lang/log#579</a></li> <li>Set all crates to 2021 edition by <a href="https://github.com/nyurik"><code>@nyurik</code></a> in <a href="https://redirect.github.com/rust-lang/log/pull/580">rust-lang/log#580</a></li> <li>Various changes based on review by <a href="https://github.com/Thomasdezeeuw"><code>@Thomasdezeeuw</code></a> in <a href="https://redirect.github.com/rust-lang/log/pull/583">rust-lang/log#583</a></li> <li>Fix typo in file_static() method doc by <a href="https://github.com/dimo414"><code>@dimo414</code></a> in <a href="https://redirect.github.com/rust-lang/log/pull/590">rust-lang/log#590</a></li> <li>Specialize empty key value pairs by <a href="https://github.com/EFanZh"><code>@EFanZh</code></a> in <a href="https://redirect.github.com/rust-lang/log/pull/576">rust-lang/log#576</a></li> <li>Fix incorrect lifetime in Value::to_str() by <a href="https://github.com/peterjoel"><code>@peterjoel</code></a> in <a href="https://redirect.github.com/rust-lang/log/pull/587">rust-lang/log#587</a></li> <li>Remove some API of the key-value feature by <a href="https://github.com/Thomasdezeeuw"><code>@Thomasdezeeuw</code></a> in <a href="https://redirect.github.com/rust-lang/log/pull/585">rust-lang/log#585</a></li> <li>Add logcontrol-log and log-reload by <a href="https://github.com/swsnr"><code>@swsnr</code></a> in <a href="https://redirect.github.com/rust-lang/log/pull/595">rust-lang/log#595</a></li> <li>Add Serialization section to kv::Value docs by <a href="https://github.com/Thomasdezeeuw"><code>@Thomasdezeeuw</code></a> in <a href="https://redirect.github.com/rust-lang/log/pull/593">rust-lang/log#593</a></li> <li>Rename Value::to_str to to_cow_str by <a href="https://github.com/Thomasdezeeuw"><code>@Thomasdezeeuw</code></a> in <a href="https://redirect.github.com/rust-lang/log/pull/592">rust-lang/log#592</a></li> <li>Clarify documentation and simplify initialization of <code>STATIC_MAX_LEVEL</code> by <a href="https://github.com/ptosi"><code>@ptosi</code></a> in <a href="https://redirect.github.com/rust-lang/log/pull/594">rust-lang/log#594</a></li> <li>Update docs to 2021 edition, test by <a href="https://github.com/nyurik"><code>@nyurik</code></a> in <a href="https://redirect.github.com/rust-lang/log/pull/577">rust-lang/log#577</a></li> <li>Add "alterable_logger" link to README.md by <a href="https://github.com/brummer-simon"><code>@brummer-simon</code></a> in <a href="https://redirect.github.com/rust-lang/log/pull/589">rust-lang/log#589</a></li> <li>Normalize line ending by <a href="https://github.com/EFanZh"><code>@EFanZh</code></a> in <a href="https://redirect.github.com/rust-lang/log/pull/602">rust-lang/log#602</a></li> <li>Remove <code>ok_or</code> in favor of <code>Option::ok_or</code> by <a href="https://github.com/AngelicosPhosphoros"><code>@AngelicosPhosphoros</code></a> in <a href="https://redirect.github.com/rust-lang/log/pull/607">rust-lang/log#607</a></li> <li>Use <code>Acquire</code> ordering for initialization check by <a href="https://github.com/AngelicosPhosphoros"><code>@AngelicosPhosphoros</code></a> in <a href="https://redirect.github.com/rust-lang/log/pull/610">rust-lang/log#610</a></li> <li>Get structured logging API ready for stabilization by <a href="https://github.com/KodrAus"><code>@KodrAus</code></a> in <a href="https://redirect.github.com/rust-lang/log/pull/613">rust-lang/log#613</a></li> </ul> <h2>New Contributors</h2> <ul> <li><a href="https://github.com/nyurik"><code>@nyurik</code></a> made their first contribution in <a href="https://redirect.github.com/rust-lang/log/pull/578">rust-lang/log#578</a></li> <li><a href="https://github.com/dimo414"><code>@dimo414</code></a> made their first contribution in <a href="https://redirect.github.com/rust-lang/log/pull/590">rust-lang/log#590</a></li> <li><a href="https://github.com/peterjoel"><code>@peterjoel</code></a> made their first contribution in <a href="https://redirect.github.com/rust-lang/log/pull/587">rust-lang/log#587</a></li> <li><a href="https://github.com/ptosi"><code>@ptosi</code></a> made their first contribution in <a href="https://redirect.github.com/rust-lang/log/pull/594">rust-lang/log#594</a></li> <li><a href="https://github.com/brummer-simon"><code>@brummer-simon</code></a> made their first contribution in <a href="https://redirect.github.com/rust-lang/log/pull/589">rust-lang/log#589</a></li> <li><a href="https://github.com/AngelicosPhosphoros"><code>@AngelicosPhosphoros</code></a> made their first contribution in <a href="https://redirect.github.com/rust-lang/log/pull/607">rust-lang/log#607</a></li> </ul> </blockquote> </details> <details> <summary>Commits</summary> <ul> <li><a href="https://github.com/rust-lang/log/commit/3ccdc286fef3076747fe18a2a93658ea4d4ae012"><code>3ccdc28</code></a> Merge pull request <a href="https://redirect.github.com/rust-lang/log/issues/617">#617</a> from rust-lang/cargo/0.4.21</li> <li><a href="https://github.com/rust-lang/log/commit/6153cb289f0e7b80f00ae07dbe5ee41cf3d3fcb0"><code>6153cb2</code></a> prepare for 0.4.21 release</li> <li><a href="https://github.com/rust-lang/log/commit/f0f74946a4bfb02cfc407795a3499c4b69d7a290"><code>f0f7494</code></a> Merge pull request <a href="https://redirect.github.com/rust-lang/log/issues/613">#613</a> from rust-lang/feat/kv-cleanup</li> <li><a href="https://github.com/rust-lang/log/commit/2b220bf3b705f2abc0ee591c7eb17972a979da3a"><code>2b220bf</code></a> clean up structured logging example</li> <li><a href="https://github.com/rust-lang/log/commit/646e9ab9917fb79e44b6b36b8375106a1a09766c"><code>646e9ab</code></a> use original Visitor name for VisitValue</li> <li><a href="https://github.com/rust-lang/log/commit/cf85c38d3519745d60e7b891c4b2025050a8389f"><code>cf85c38</code></a> add needed subfeatures to kv_unstable</li> <li><a href="https://github.com/rust-lang/log/commit/73e953905b970ef765a86bf6cbd69bc2c5e2bac4"><code>73e9539</code></a> fix up capturing of :err</li> <li><a href="https://github.com/rust-lang/log/commit/31bb4b0ff36e458c6bef304a336b71f6342ddcc7"><code>31bb4b0</code></a> move error macros together</li> <li><a href="https://github.com/rust-lang/log/commit/ad917118a5e781d0dd60b3a75ba519ce9839ba70"><code>ad91711</code></a> support field shorthand in macros</li> <li><a href="https://github.com/rust-lang/log/commit/90a347bd836873264a393a35bfd90fe478fadae2"><code>90a347b</code></a> restore removed APIs as deprecated</li> <li>Additional commits viewable in <a href="https://github.com/rust-lang/log/compare/0.4.20...0.4.21">compare view</a></li> </ul> </details> <br /> Updates `syn` from 2.0.50 to 2.0.52 <details> <summary>Release notes</summary> <p><em>Sourced from <a href="https://github.com/dtolnay/syn/releases">syn's releases</a>.</em></p> <blockquote> <h2>2.0.52</h2> <ul> <li>Add an expression parser that uses match-arm's boundary rules (<a href="https://redirect.github.com/dtolnay/syn/issues/1593">#1593</a>)</li> </ul> <h2>2.0.51</h2> <ul> <li>Resolve non_local_definitions warnings in generated code under rustc 1.78-nightly</li> </ul> </blockquote> </details> <details> <summary>Commits</summary> <ul> <li><a href="https://github.com/dtolnay/syn/commit/07ede6a6b31adeb3a18899ada1f352f63b3a36b9"><code>07ede6a</code></a> Release 2.0.52</li> <li><a href="https://github.com/dtolnay/syn/commit/acbcfbc8c113fa1603469c9ad329d061ee74662e"><code>acbcfbc</code></a> Merge pull request <a href="https://redirect.github.com/dtolnay/syn/issues/1593">#1593</a> from dtolnay/boundary</li> <li><a href="https://github.com/dtolnay/syn/commit/4924a993dce23abe65128ac318dd662d1e2ceef2"><code>4924a99</code></a> Add an expression parser that uses match-arm's boundary rules</li> <li><a href="https://github.com/dtolnay/syn/commit/e06122bf2cfd31bd7f70304694477dd292fe7e1e"><code>e06122b</code></a> Resolve unnecessary_get_then_check clippy lint</li> <li><a href="https://github.com/dtolnay/syn/commit/018fc5a6298491525387910cb359a9ec618abe54"><code>018fc5a</code></a> Update test suite to nightly-2024-02-27</li> <li><a href="https://github.com/dtolnay/syn/commit/5e15a9b412cb1e2df481e3470e1be8defaee4495"><code>5e15a9b</code></a> Release 2.0.51</li> <li><a href="https://github.com/dtolnay/syn/commit/7e0d4e1f43a879078595f0a3876484a1920ab8f8"><code>7e0d4e1</code></a> Resolve non_local_definitions warning in debug impls</li> <li><a href="https://github.com/dtolnay/syn/commit/8667ad97c1d4e75ac1bb323fb5c7849269814145"><code>8667ad9</code></a> Ignore module_name_repetitions pedantic clippy lint in codegen</li> <li><a href="https://github.com/dtolnay/syn/commit/1fc32000e25bf8fda7371071073f91e012ddf808"><code>1fc3200</code></a> Update test suite to nightly-2024-02-26</li> <li><a href="https://github.com/dtolnay/syn/commit/07a2065576b27dcf0c104f56379cc446d2f3824b"><code>07a2065</code></a> Update test suite to nightly-2024-02-23</li> <li>See full diff in <a href="https://github.com/dtolnay/syn/compare/2.0.50...2.0.52">compare view</a></li> </ul> </details> <br /> Updates `clap` from 4.5.1 to 4.5.3 <details> <summary>Release notes</summary> <p><em>Sourced from <a href="https://github.com/clap-rs/clap/releases">clap's releases</a>.</em></p> <blockquote> <h2>v4.5.3</h2> <h2>[4.5.3] - 2024-03-15</h2> <h3>Internal</h3> <ul> <li><em>(derive)</em> Update <code>heck</code></li> </ul> <h2>v4.5.2</h2> <h2>[4.5.2] - 2024-03-06</h2> <h3>Fixes</h3> <ul> <li><em>(macros)</em> Silence a warning</li> </ul> </blockquote> </details> <details> <summary>Changelog</summary> <p><em>Sourced from <a href="https://github.com/clap-rs/clap/blob/master/CHANGELOG.md">clap's changelog</a>.</em></p> <blockquote> <h2>[4.5.3] - 2024-03-15</h2> <h3>Internal</h3> <ul> <li><em>(derive)</em> Update <code>heck</code></li> </ul> <h2>[4.5.2] - 2024-03-06</h2> <h3>Fixes</h3> <ul> <li><em>(macros)</em> Silence a warning</li> </ul> </blockquote> </details> <details> <summary>Commits</summary> <ul> <li><a href="https://github.com/clap-rs/clap/commit/4e07b438584bb8a19e37599d4c5b11797bec5579"><code>4e07b43</code></a> chore: Release</li> <li><a href="https://github.com/clap-rs/clap/commit/8247c7ddf05d8023729ac180d8e8df260f1da5ff"><code>8247c7d</code></a> docs: Update changelog</li> <li><a href="https://github.com/clap-rs/clap/commit/677c52ce0870115845a4c42e204f6c049b81a1e7"><code>677c52c</code></a> chore: Update <code>heck</code> requirement (<a href="https://redirect.github.com/clap-rs/clap/issues/5396">#5396</a>)</li> <li><a href="https://github.com/clap-rs/clap/commit/f65d421607ba16c3175ffe76a20820f123b6c4cb"><code>f65d421</code></a> chore: Release</li> <li><a href="https://github.com/clap-rs/clap/commit/886b2729e419114bf42f1a92c66d346c81aa8f33"><code>886b272</code></a> docs: Update changelog</li> <li><a href="https://github.com/clap-rs/clap/commit/3ba429752fdb19b7a1c2e151c41d5141ad5b9295"><code>3ba4297</code></a> Merge pull request <a href="https://redirect.github.com/clap-rs/clap/issues/5386">#5386</a> from amaanq/static-var-name</li> <li><a href="https://github.com/clap-rs/clap/commit/2aea9504c4894b3bddf9cd4d2d6cba889307c157"><code>2aea950</code></a> fix: Use SCREAMING_SNAKE_CASE for static variable <code>authors</code></li> <li><a href="https://github.com/clap-rs/clap/commit/690f5557d7f25904c31ec9f2a3c3657cbb68c98e"><code>690f555</code></a> Merge pull request <a href="https://redirect.github.com/clap-rs/clap/issues/5382">#5382</a> from clap-rs/renovate/pre-commit-action-3.x</li> <li><a href="https://github.com/clap-rs/clap/commit/a2aa644368ec19026b16b870ec32dc57b325ba9b"><code>a2aa644</code></a> chore(deps): update compatible (dev) (<a href="https://redirect.github.com/clap-rs/clap/issues/5381">#5381</a>)</li> <li><a href="https://github.com/clap-rs/clap/commit/c233de53c0cca4281f444cf16d16d161bc9c3cab"><code>c233de5</code></a> chore(deps): update pre-commit/action action to v3.0.1</li> <li>Additional commits viewable in <a href="https://github.com/clap-rs/clap/compare/clap_complete-v4.5.1...v4.5.3 ">compare view</a></li> </ul> </details> <br /> Dependabot will resolve any conflicts with this PR as long as you don't alter it yourself. You can also trigger a rebase manually by commenting `@dependabot rebase`. [//]: # (dependabot-automerge-start) [//]: # (dependabot-automerge-end) --- <details> <summary>Dependabot commands and options</summary> <br /> You can trigger Dependabot actions by commenting on this PR: - `@dependabot rebase` will rebase this PR - `@dependabot recreate` will recreate this PR, overwriting any edits that have been made to it - `@dependabot merge` will merge this PR after your CI passes on it - `@dependabot squash and merge` will squash and merge this PR after your CI passes on it - `@dependabot cancel merge` will cancel a previously requested merge and block automerging - `@dependabot reopen` will reopen this PR if it is closed - `@dependabot close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually - `@dependabot show <dependency name> ignore conditions` will show all of the ignore conditions of the specified dependency - `@dependabot ignore <dependency name> major version` will close this group update PR and stop Dependabot creating any more for the specific dependency's major version (unless you unignore this specific dependency's major version or upgrade to it yourself) - `@dependabot ignore <dependency name> minor version` will close this group update PR and stop Dependabot creating any more for the specific dependency's minor version (unless you unignore this specific dependency's minor version or upgrade to it yourself) - `@dependabot ignore <dependency name>` will close this group update PR and stop Dependabot creating any more for the specific dependency (unless you unignore this specific dependency or upgrade to it yourself) - `@dependabot unignore <dependency name>` will remove all of the ignore conditions of the specified dependency - `@dependabot unignore <dependency name> <ignore condition>` will remove the ignore condition of the specified dependency and ignore conditions </details> Signed-off-by:
dependabot[bot] <[email protected]> Co-authored-by:
dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
-
- Mar 13, 2024
-
-
- Mar 11, 2024
-
-
Andrei Eres authored
Fixes https://github.com/paritytech/polkadot-sdk/issues/3528 ```rust latency: mean_latency_ms = 30 // common sense std_dev = 2.0 // common sense n_validators = 300 // max number of validators, from chain config n_cores = 60 // 300/5 max_validators_per_core = 5 // default min_pov_size = 5120 // max max_pov_size = 5120 // max peer_bandwidth = 44040192 // from the Parity's kusama validators bandwidth = 44040192 // from the Parity's kusama validators connectivity = 90 // we need to be connected to 90-95% of peers ```
-
- Mar 08, 2024
-
-
cuinix authored
Signed-off-by:
cuinix <[email protected]> Co-authored-by:
Bastian Köcher <[email protected]>
-
- Mar 07, 2024
-
-
André Silva authored
Moves [substrate-bip39](https://github.com/paritytech/substrate-bip39) into substrate. All git history is preserved. Dependencies have been updated to use the same version as the rest of the repo. Fixes https://github.com/paritytech/polkadot-sdk/issues/1934 . --------- Co-authored-by:
Maciej Hirsz <[email protected]> Co-authored-by:
Maciej Hirsz <[email protected]> Co-authored-by:
Gav Wood <[email protected]> Co-authored-by:
Stanislav Tkach <[email protected]> Co-authored-by:
Robert Habermeier <[email protected]> Co-authored-by:
Pierre Krieger <[email protected]> Co-authored-by:
Demi M. Obenour <[email protected]> Co-authored-by:
NikVolf <[email protected]> Co-authored-by:
Bastian Köcher <[email protected]> Co-authored-by:
Benjamin Kampmann <[email protected]> Co-authored-by:
Maciej Hirsz <[email protected]> Co-authored-by:
cheme <[email protected]> Co-authored-by:
adoerr <[email protected]> Co-authored-by:
Jun Jiang <[email protected]> Co-authored-by:
Dan Shields <[email protected]> Co-authored-by:
Michal Kucharczyk <[email protected]>
-
- Mar 01, 2024
-
-
Andrei Eres authored
### What's been done - `subsystem-bench` has been split into two parts: a cli benchmark runner and a library. - The cli runner is quite simple. It just allows us to run `.yaml` based test sequences. Now it should only be used to run benchmarks during development. - The library is used in the cli runner and in regression tests. Some code is changed to make the library independent of the runner. - Added first regression tests for availability read and write that replicate existing test sequences. ### How we run regression tests - Regression tests are simply rust integration tests without the harnesses. - They should only be compiled under the `subsystem-benchmarks` feature to prevent them from running with other tests. - This doesn't work when running tests with `nextest` in CI, so additional filters have been added to the `nextest` runs. - Each benchmark run takes a different time in the beginning, so we "warm up" the tests until their CPU usage differs by only 1%. - After the warm-up, we run the benchmarks a few more times and compare the average with the exception using a precision. ### What is still wrong? - I haven't managed to set up approval voting tests. The spread of their results is too large and can't be narrowed down in a reasonable amount of time in the warm-up phase. - The tests start an unconfigurable prometheus endpoint inside, which causes errors because they use the same 9999 port. I disable it with a flag, but I think it's better to extract the endpoint launching outside the test, as we already do with `valgrind` and `pyroscope`. But we still use `prometheus` inside the tests. ### Future work * https://github.com/paritytech/polkadot-sdk/issues/3528 * https://github.com/paritytech/polkadot-sdk/issues/3529 * https://github.com/paritytech/polkadot-sdk/issues/3530 * https://github.com/paritytech/polkadot-sdk/issues/3531 --------- Co-authored-by:
Alexander Samusev <[email protected]>
-
- Feb 20, 2024
-
-
 Oliver Tale-Yazdi authored
Oliver Tale-Yazdi authoredLifting some more dependencies to the workspace. Just using the most-often updated ones for now. It can be reproduced locally. ```sh # First you can check if there would be semver incompatible bumps (looks good in this case): $ zepter transpose dependency lift-to-workspace --ignore-errors syn quote thiserror "regex:^serde.*" # Then apply the changes: $ zepter transpose dependency lift-to-workspace --version-resolver=highest syn quote thiserror "regex:^serde.*" --fix # And format the changes: $ taplo format --config .config/taplo.toml ``` --------- Signed-off-by:Oliver Tale-Yazdi <[email protected]>
-
- Feb 19, 2024
-
-
dependabot[bot] authored
Bumps the known_good_semver group with 1 update: [clap](https://github.com/clap-rs/clap). Updates `clap` from 4.5.0 to 4.5.1 <details> <summary>Release notes</summary> <p><em>Sourced from <a href="https://github.com/clap-rs/clap/releases">clap's releases</a>.</em></p> <blockquote> <h2>v4.5.1</h2> <h2>[4.5.1] - 2024-02-16</h2> <h3>Fixes</h3> <ul> <li><em>(error)</em> Include suggestion to add <code>--</code> even if there is a "did you mean" so long as <code>last</code> or <code>trailing_var_arg</code> is used</li> </ul> </blockquote> </details> <details> <summary>Changelog</summary> <p><em>Sourced from <a href="https://github.com/clap-rs/clap/blob/master/CHANGELOG.md">clap's changelog</a>.</em></p> <blockquote> <h2>[4.5.1] - 2024-02-16</h2> <h3>Fixes</h3> <ul> <li><em>(error)</em> Include suggestion to add <code>--</code> even if there is a "did you mean" so long as <code>last</code> or <code>trailing_var_arg</code> is used</li> </ul> </blockquote> </details> <details> <summary>Commits</summary> <ul> <li><a href="https://github.com/clap-rs/clap/commit/0c01b5558de0a1a513a2af429981099e550d1a78"><code>0c01b55</code></a> chore: Release</li> <li><a href="https://github.com/clap-rs/clap/commit/08e0b5bde4b45567be98d12e7d394762fa8da6a4"><code>08e0b5b</code></a> docs: Update changelog</li> <li><a href="https://github.com/clap-rs/clap/commit/f2c4e6ec740cce29cea3fd7232e4d2716f089fc2"><code>f2c4e6e</code></a> Merge pull request <a href="https://redirect.github.com/clap-rs/clap/issues/5359">#5359</a> from poliorcetics/ab/push-szymvyzpmnqx</li> <li><a href="https://github.com/clap-rs/clap/commit/e782775229081697e47d340a155d6b087eeb46f8"><code>e782775</code></a> fix(complete): Handle newlines in command/arg descriptions</li> <li><a href="https://github.com/clap-rs/clap/commit/fba7c8597bf3028400d6f6a22d83cedb7a2bd5a5"><code>fba7c85</code></a> test(complete): Show newline issue</li> <li><a href="https://github.com/clap-rs/clap/commit/8a7a13a5618cfdc4ff328624a5266e7b4d88649a"><code>8a7a13a</code></a> chore: Release</li> <li><a href="https://github.com/clap-rs/clap/commit/7b3a3e1e5eee57fc37110343b980cbe8170d20ad"><code>7b3a3e1</code></a> docs: Update changelog</li> <li><a href="https://github.com/clap-rs/clap/commit/7b624ca74336f6f14f01007b9039990d53acda0f"><code>7b624ca</code></a> Merge pull request <a href="https://redirect.github.com/clap-rs/clap/issues/5356">#5356</a> from epage/escape</li> <li><a href="https://github.com/clap-rs/clap/commit/446328a8d3cdaac28884bf8fdfcc85f35c8b5134"><code>446328a</code></a> fix(error): Include -- in more cases</li> <li><a href="https://github.com/clap-rs/clap/commit/7de6df878238ca8e3d9723bb9650f7fe9470d8bd"><code>7de6df8</code></a> test(error): Show existing last behavior</li> <li>Additional commits viewable in <a href="https://github.com/clap-rs/clap/compare/clap_complete-v4.5.0...clap_complete-v4.5.1">compare view</a></li> </ul> </details> <br /> [](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores ) Dependabot will resolve any conflicts with this PR as long as you don't alter it yourself. You can also trigger a rebase manually by commenting `@dependabot rebase`. [//]: # (dependabot-automerge-start) [//]: # (dependabot-automerge-end) --- <details> <summary>Dependabot commands and options</summary> <br /> You can trigger Dependabot actions by commenting on this PR: - `@dependabot rebase` will rebase this PR - `@dependabot recreate` will recreate this PR, overwriting any edits that have been made to it - `@dependabot merge` will merge this PR after your CI passes on it - `@dependabot squash and merge` will squash and merge this PR after your CI passes on it - `@dependabot cancel merge` will cancel a previously requested merge and block automerging - `@dependabot reopen` will reopen this PR if it is closed - `@dependabot close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually - `@dependabot show <dependency name> ignore conditions` will show all of the ignore conditions of the specified dependency - `@dependabot ignore <dependency name> major version` will close this group update PR and stop Dependabot creating any more for the specific dependency's major version (unless you unignore this specific dependency's major version or upgrade to it yourself) - `@dependabot ignore <dependency name> minor version` will close this group update PR and stop Dependabot creating any more for the specific dependency's minor version (unless you unignore this specific dependency's minor version or upgrade to it yourself) - `@dependabot ignore <dependency name>` will close this group update PR and stop Dependabot creating any more for the specific dependency (unless you unignore this specific dependency or upgrade to it yourself) - `@dependabot unignore <dependency name>` will remove all of the ignore conditions of the specified dependency - `@dependabot unignore <dependency name> <ignore condition>` will remove the ignore condition of the specified dependency and ignore conditions </details> Signed-off-by:
-
- Feb 16, 2024
-
-
dependabot[bot] authored
Bumps the known_good_semver group with 6 updates: | Package | From | To | | --- | --- | --- | | [serde](https://github.com/serde-rs/serde) | `1.0.195` | `1.0.196` | | [serde_json](https://github.com/serde-rs/json) | `1.0.111` | `1.0.113` | | [clap](https://github.com/clap-rs/clap) | `4.4.18` | `4.5.0` | | [syn](https://github.com/dtolnay/syn) | `2.0.48` | `2.0.49` | | [serde_yaml](https://github.com/dtolnay/serde-yaml) | `0.9.30` | `0.9.31` | | [serde_derive](https://github.com/serde-rs/serde) | `1.0.195` | `1.0.196` | Updates `serde` from 1.0.195 to 1.0.196 <details> <summary>Release notes</summary> <p><em>Sourced from <a href="https://github.com/serde-rs/serde/releases">serde's releases</a>.</em></p> <blockquote> <h2>v1.0.196</h2> <ul> <li>Improve formatting of "invalid type" error messages involving floats (<a href="https://redirect.github.com/serde-rs/serde/issues/2682">#2682</a>)</li> </ul> </blockquote> </details> <details> <summary>Commits</summary> <ul> <li><a href="https://github.com/serde-rs/serde/commit/ede9762a583c3cc3b87c10a53551828fad339525"><code>ede9762</code></a> Release 1.0.196</li> <li><a href="https://github.com/serde-rs/serde/commit/d438c2d67bf30e3edab31c2272c4829c12cf4cb5"><code>d438c2d</code></a> Merge pull request <a href="https://redirect.github.com/serde-rs/serde/issues/2682">#2682</a> from dtolnay/decimalpoint</li> <li><a href="https://github.com/serde-rs/serde/commit/bef110b92a171ac568a47339f5bd97938a8c9da2"><code>bef110b</code></a> Format Unexpected::Float with decimal point</li> <li><a href="https://github.com/serde-rs/serde/commit/b971ef11d1b53da7673e0c8199e87509c003c1a8"><code>b971ef1</code></a> Merge pull request <a href="https://redirect.github.com/serde-rs/serde/issues/2681">#2681</a> from dtolnay/workspacedeps</li> <li><a href="https://github.com/serde-rs/serde/commit/29d9f693996d199748136d5561a971ed68626724"><code>29d9f69</code></a> Fix workspace.dependencies default-features future compat warning</li> <li><a href="https://github.com/serde-rs/serde/commit/aecb4083bde754155752f5d7d442b64eb7dc636f"><code>aecb408</code></a> Sort workspace dependencies</li> <li><a href="https://github.com/serde-rs/serde/commit/1c675ab3a38e46df4e62465800970f8b20a2055d"><code>1c675ab</code></a> Merge pull request <a href="https://redirect.github.com/serde-rs/serde/issues/2678">#2678</a> from rodoufu/workspaceDependencies</li> <li><a href="https://github.com/serde-rs/serde/commit/dd619630a337139424725697ccd9a9f7596a2d3a"><code>dd61963</code></a> Adding workspace dependencies</li> <li><a href="https://github.com/serde-rs/serde/commit/111803ab0768d010c606f2fc0d0add12750d5eef"><code>111803a</code></a> Merge pull request <a href="https://redirect.github.com/serde-rs/serde/issues/2673">#2673</a> from Sky9x/msrv-badge</li> <li><a href="https://github.com/serde-rs/serde/commit/0024f74f34fbbdc44a7b22457faebe36c5cbe7f8"><code>0024f74</code></a> Use shields.io's MSRV badges</li> <li>See full diff in <a href="https://github.com/serde-rs/serde/compare/v1.0.195...v1.0.196">compare view</a></li> </ul> </details> <br /> Updates `serde_json` from 1.0.111 to 1.0.113 <details> <summary>Release notes</summary> <p><em>Sourced from <a href="https://github.com/serde-rs/json/releases">serde_json's releases</a>.</em></p> <blockquote> <h2>v1.0.113</h2> <ul> <li>Add <code>swap_remove</code> and <code>shift_remove</code> methods on Map (<a href="https://redirect.github.com/serde-rs/json/issues/1109">#1109</a>)</li> </ul> <h2>v1.0.112</h2> <ul> <li>Improve formatting of "invalid type" error messages involving floats (<a href="https://redirect.github.com/serde-rs/json/issues/1107">#1107</a>)</li> </ul> </blockquote> </details> <details> <summary>Commits</summary> <ul> <li><a href="https://github.com/serde-rs/json/commit/09d865b34b9701be52764dc9bf571b1a16e9d3dc"><code>09d865b</code></a> Release 1.0.113</li> <li><a href="https://github.com/serde-rs/json/commit/5aeab4eaf69d7959f013f8081865c264d6c00551"><code>5aeab4e</code></a> Merge pull request <a href="https://redirect.github.com/serde-rs/json/issues/1109">#1109</a> from serde-rs/remove</li> <li><a href="https://github.com/serde-rs/json/commit/ca3c2ca3696cab79b8b279be7569ee1647250f1e"><code>ca3c2ca</code></a> Add swap_remove and shift_remove methods on Map</li> <li><a href="https://github.com/serde-rs/json/commit/7fece969e3b480ec620419d65c2aeb08776bebcb"><code>7fece96</code></a> Release 1.0.112</li> <li><a href="https://github.com/serde-rs/json/commit/6a6d2bbd9e8b8bd72573b863f12a4ec991f33232"><code>6a6d2bb</code></a> Merge pull request <a href="https://redirect.github.com/serde-rs/json/issues/1107">#1107</a> from serde-rs/unexpectedfloat</li> <li><a href="https://github.com/serde-rs/json/commit/83d7bad54ba5db3a44198d6df0ff2e81621683fa"><code>83d7bad</code></a> Format f64 in error messages using ryu</li> <li><a href="https://github.com/serde-rs/json/commit/107c2d1c42817f0d71f07a4d5b0ea2f29dbce8b8"><code>107c2d1</code></a> Merge pull request <a href="https://redirect.github.com/serde-rs/json/issues/1106">#1106</a> from serde-rs/invalidvalue</li> <li><a href="https://github.com/serde-rs/json/commit/62ca3e4c01c2e62cd5c2a32e9104f386e5ce7808"><code>62ca3e4</code></a> Handle Unexpected::Unit in Error::invalid_value</li> <li><a href="https://github.com/serde-rs/json/commit/296fafb8f32e8442ef8e4d5725c15ffca726b288"><code>296fafb</code></a> Factor out JSON-specific Display impl for serde::de::Unexpected</li> <li><a href="https://github.com/serde-rs/json/commit/e56cc696bd7c112e5dd4ccfa23d094c3a1c1c1ff"><code>e56cc69</code></a> Merge pull request <a href="https://redirect.github.com/serde-rs/json/issues/1105">#1105</a> from keienWang/master</li> <li>Additional commits viewable in <a href="https://github.com/serde-rs/json/compare/v1.0.111...v1.0.113">compare view</a></li> </ul> </details> <br /> Updates `clap` from 4.4.18 to 4.5.0 <details> <summary>Changelog</summary> <p><em>Sourced from <a href="https://github.com/clap-rs/clap/blob/master/CHANGELOG.md">clap's changelog</a>.</em></p> <blockquote> <h2>[4.5.0] - 2024-02-08</h2> <h3>Compatibility</h3> <ul> <li>Update MSRV to 1.74</li> </ul> </blockquote> </details> <details> <summary>Commits</summary> <ul> <li><a href="https://github.com/clap-rs/clap/commit/a751c5fe65cd33cb09e85ff3039b4fd0182cdb6e"><code>a751c5f</code></a> chore: Release</li> <li><a href="https://github.com/clap-rs/clap/commit/9ec6c942b81c370a8c14652e42295933244555ac"><code>9ec6c94</code></a> chore: Release</li> <li><a href="https://github.com/clap-rs/clap/commit/0735119775c2d27fef6b3c232cb9ef2fcbbd963f"><code>0735119</code></a> docs: Update changelog</li> <li><a href="https://github.com/clap-rs/clap/commit/c4d3959506f5068f86ffb7ab34b622bd2da40dd8"><code>c4d3959</code></a> Merge pull request <a href="https://redirect.github.com/clap-rs/clap/issues/5344">#5344</a> from epage/encode</li> <li><a href="https://github.com/clap-rs/clap/commit/f750e577789e1dd34c6950d8c8fe16d1bfd1f49c"><code>f750e57</code></a> fix(lex): Use new-ish OsStr API</li> <li><a href="https://github.com/clap-rs/clap/commit/1d9a554cdfddffcb92d197706b9720e2760cb443"><code>1d9a554</code></a> Merge pull request <a href="https://redirect.github.com/clap-rs/clap/issues/5343">#5343</a> from epage/msrv</li> <li><a href="https://github.com/clap-rs/clap/commit/4b45d361b1b96eb1f37b7d1db2684203ca828a94"><code>4b45d36</code></a> chore: Update MSRV to 1.74</li> <li><a href="https://github.com/clap-rs/clap/commit/55b1f945157d4d0e480dea6c492e04d0b541088a"><code>55b1f94</code></a> Merge pull request <a href="https://redirect.github.com/clap-rs/clap/issues/5342">#5342</a> from epage/divan</li> <li><a href="https://github.com/clap-rs/clap/commit/ea77b98da3f321069ae136a241a2d266c2b28bd7"><code>ea77b98</code></a> test(complete): Make it order independent</li> <li><a href="https://github.com/clap-rs/clap/commit/b0fea2bac60819bdb042e10c032817fded67f815"><code>b0fea2b</code></a> test(bench): Switch to divan</li> <li>Additional commits viewable in <a href="https://github.com/clap-rs/clap/compare/v4.4.18...clap_complete-v4.5.0">compare view</a></li> </ul> </details> <br /> Updates `syn` from 2.0.48 to 2.0.49 <details> <summary>Release notes</summary> <p><em>Sourced from <a href="https://github.com/dtolnay/syn/releases">syn's releases</a>.</em></p> <blockquote> <h2>2.0.49</h2> <ul> <li>Improve error location when parsing from an empty string literal using <code>LitStr::parse</code> (<a href="https://redirect.github.com/dtolnay/syn/issues/1590">#1590</a>)</li> </ul> </blockquote> </details> <details> <summary>Commits</summary> <ul> <li><a href="https://github.com/dtolnay/syn/commit/e64c0636042bcd8cf56f9e6c3e828a49cb434649"><code>e64c063</code></a> Release 2.0.49</li> <li><a href="https://github.com/dtolnay/syn/commit/981359c5f46f25f3db42d1b341cc607f634688e7"><code>981359c</code></a> Merge pull request <a href="https://redirect.github.com/dtolnay/syn/issues/1590">#1590</a> from dtolnay/streof</li> <li><a href="https://github.com/dtolnay/syn/commit/51298d40a447b9e5b3cd8c898c2ea9d24b31cd6d"><code>51298d4</code></a> Improve error location at eof in LitStr::parse</li> <li><a href="https://github.com/dtolnay/syn/commit/270c63384a9d891f65880a03a5a92f0bf4605bbf"><code>270c633</code></a> Update test suite to nightly-2024-02-13</li> <li><a href="https://github.com/dtolnay/syn/commit/dc9cf16b9b0601d2d393d059c46a8f8e0220cc21"><code>dc9cf16</code></a> Remove FilterAttrs trait when unused</li> <li><a href="https://github.com/dtolnay/syn/commit/7dcfac79eda716fa806d68cc0aa811f3be717dc0"><code>7dcfac7</code></a> Ignore dead_code warning in test</li> <li><a href="https://github.com/dtolnay/syn/commit/98318441089f9a9bb596fc010ed14c3b593d4bda"><code>9831844</code></a> Update signature of Emitter::emit_diagnostic in nightly-2024-02-07</li> <li><a href="https://github.com/dtolnay/syn/commit/9e8033f63da93dfb6a3e698449c6edff5e56727d"><code>9e8033f</code></a> Update test suite to nightly-2024-02-07</li> <li><a href="https://github.com/dtolnay/syn/commit/cb3348cd94be50995054796facdfa055b6e0e9e8"><code>cb3348c</code></a> Update test suite to nightly-2024-01-23</li> <li><a href="https://github.com/dtolnay/syn/commit/15b9dbcd67bc56f3da7d33bbede46f7380fc7164"><code>15b9dbc</code></a> Update test suite to nightly-2024-01-19</li> <li>Additional commits viewable in <a href="https://github.com/dtolnay/syn/compare/2.0.48...2.0.49">compare view</a></li> </ul> </details> <br /> Updates `serde_yaml` from 0.9.30 to 0.9.31 <details> <summary>Release notes</summary> <p><em>Sourced from <a href="https://github.com/dtolnay/serde-yaml/releases">serde_yaml's releases</a>.</em></p> <blockquote> <h2>0.9.31</h2> <ul> <li>Add <code>swap_remove</code> and <code>shift_remove</code> methods on Mapping (<a href="https://redirect.github.com/dtolnay/serde-yaml/issues/408">#408</a>)</li> </ul> </blockquote> </details> <details> <summary>Commits</summary> <ul> <li><a href="https://github.com/dtolnay/serde-yaml/commit/2a77483b23897115bdd69af32ae34d593268d555"><code>2a77483</code></a> Release 0.9.31</li> <li><a href="https://github.com/dtolnay/serde-yaml/commit/d8d1a839cf42ef4627c66bebd743f5fecd24e3ed"><code>d8d1a83</code></a> Merge pull request <a href="https://redirect.github.com/dtolnay/serde-yaml/issues/408">#408</a> from dtolnay/remove</li> <li><a href="https://github.com/dtolnay/serde-yaml/commit/f8a99a496836ccfa6c547af9136986d13011be98"><code>f8a99a4</code></a> Add swap_remove and shift_remove methods on Mapping</li> <li><a href="https://github.com/dtolnay/serde-yaml/commit/8b26413e3307e39329dc68a96b065058aec38f9a"><code>8b26413</code></a> Work around dead_code warning in tests</li> <li>See full diff in <a href="https://github.com/dtolnay/serde-yaml/compare/0.9.30...0.9.31">compare view</a></li> </ul> </details> <br /> Updates `serde_derive` from 1.0.195 to 1.0.196 <details> <summary>Release notes</summary> <p><em>Sourced from <a href="https://github.com/serde-rs/serde/releases">serde_derive's releases</a>.</em></p> <blockquote> <h2>v1.0.196</h2> <ul> <li>Improve formatting of "invalid type" error messages involving floats (<a href="https://redirect.github.com/serde-rs/serde/issues/2682">#2682</a>)</li> </ul> </blockquote> </details> <details> <summary>Commits</summary> <ul> <li><a href="https://github.com/serde-rs/serde/commit/ede9762a583c3cc3b87c10a53551828fad339525"><code>ede9762</code></a> Release 1.0.196</li> <li><a href="https://github.com/serde-rs/serde/commit/d438c2d67bf30e3edab31c2272c4829c12cf4cb5"><code>d438c2d</code></a> Merge pull request <a href="https://redirect.github.com/serde-rs/serde/issues/2682">#2682</a> from dtolnay/decimalpoint</li> <li><a href="https://github.com/serde-rs/serde/commit/bef110b92a171ac568a47339f5bd97938a8c9da2"><code>bef110b</code></a> Format Unexpected::Float with decimal point</li> <li><a href="https://github.com/serde-rs/serde/commit/b971ef11d1b53da7673e0c8199e87509c003c1a8"><code>b971ef1</code></a> Merge pull request <a href="https://redirect.github.com/serde-rs/serde/issues/2681">#2681</a> from dtolnay/workspacedeps</li> <li><a href="https://github.com/serde-rs/serde/commit/29d9f693996d199748136d5561a971ed68626724"><code>29d9f69</code></a> Fix workspace.dependencies default-features future compat warning</li> <li><a href="https://github.com/serde-rs/serde/commit/aecb4083bde754155752f5d7d442b64eb7dc636f"><code>aecb408</code></a> Sort workspace dependencies</li> <li><a href="https://github.com/serde-rs/serde/commit/1c675ab3a38e46df4e62465800970f8b20a2055d"><code>1c675ab</code></a> Merge pull request <a href="https://redirect.github.com/serde-rs/serde/issues/2678">#2678</a> from rodoufu/workspaceDependencies</li> <li><a href="https://github.com/serde-rs/serde/commit/dd619630a337139424725697ccd9a9f7596a2d3a"><code>dd61963</code></a> Adding workspace dependencies</li> <li><a href="https://github.com/serde-rs/serde/commit/111803ab0768d010c606f2fc0d0add12750d5eef"><code>111803a</code></a> Merge pull request <a href="https://redirect.github.com/serde-rs/serde/issues/2673">#2673</a> from Sky9x/msrv-badge</li> <li><a href="https://github.com/serde-rs/serde/commit/0024f74f34fbbdc44a7b22457faebe36c5cbe7f8"><code>0024f74</code></a> Use shields.io's MSRV badges</li> <li>See full diff in <a href="https://github.com/serde-rs/serde/compare/v1.0.195...v1.0.196 ">compare view</a></li> </ul> </details> <br /> Dependabot will resolve any conflicts with this PR as long as you don't alter it yourself. You can also trigger a rebase manually by commenting `@dependabot rebase`. [//]: # (dependabot-automerge-start) [//]: # (dependabot-automerge-end) --- <details> <summary>Dependabot commands and options</summary> <br /> You can trigger Dependabot actions by commenting on this PR: - `@dependabot rebase` will rebase this PR - `@dependabot recreate` will recreate this PR, overwriting any edits that have been made to it - `@dependabot merge` will merge this PR after your CI passes on it - `@dependabot squash and merge` will squash and merge this PR after your CI passes on it - `@dependabot cancel merge` will cancel a previously requested merge and block automerging - `@dependabot reopen` will reopen this PR if it is closed - `@dependabot close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually - `@dependabot show <dependency name> ignore conditions` will show all of the ignore conditions of the specified dependency - `@dependabot ignore <dependency name> major version` will close this group update PR and stop Dependabot creating any more for the specific dependency's major version (unless you unignore this specific dependency's major version or upgrade to it yourself) - `@dependabot ignore <dependency name> minor version` will close this group update PR and stop Dependabot creating any more for the specific dependency's minor version (unless you unignore this specific dependency's minor version or upgrade to it yourself) - `@dependabot ignore <dependency name>` will close this group update PR and stop Dependabot creating any more for the specific dependency (unless you unignore this specific dependency or upgrade to it yourself) - `@dependabot unignore <dependency name>` will remove all of the ignore conditions of the specified dependency - `@dependabot unignore <dependency name> <ignore condition>` will remove the ignore condition of the specified dependency and ignore conditions </details> Signed-off-by:
-
- Feb 12, 2024
-
-
Oliver Tale-Yazdi authored
Changes (partial https://github.com/paritytech/polkadot-sdk/issues/994): - Set log to `0.4.20` everywhere - Lift `log` to the workspace Starting with a simpler one after seeing https://github.com/paritytech/polkadot-sdk/pull/2065 from @jsdw . This sets the `default-features` to `false` in the root and then overwrites that in each create to its original value. This is necessary since otherwise the `default` features are additive and its impossible to disable them in the crate again once they are enabled in the workspace. I am using a tool to do this, so its mostly a test to see that it works as expected. --------- Signed-off-by:
-
Andrei Eres authored
-
- Feb 08, 2024
-
-
Andrei Eres authored
This PR removes the configuration of subsystem benchmarks via CLI arguments. After this, we only keep configurations only in yaml files. It removes unnecessary code duplication
-
- Feb 06, 2024
-
-
Andrei Eres authored
1. Benchmark results are collected in a single struct. 2. The output of the results is prettified. 3. The result struct used to save the output as a yaml and store it in artifacts in a CI job. ``` $ cargo run -p polkadot-subsystem-bench --release -- test-sequence --path polkadot/node/subsystem-bench/examples/availability_read.yaml | tee output.txt $ cat output.txt polkadot/node/subsystem-bench/examples/availability_read.yaml #1 Network usage, KiB total per block Received from peers 510796.000 170265.333 Sent to peers 221.000 73.667 CPU usage, s total per block availability-recovery 38.671 12.890 Test environment 0.255 0.085 polkadot/node/subsystem-bench/examples/availability_read.yaml #2 Network usage, KiB total per block Received from peers 413633.000 137877.667 Sent to peers 353.000 117.667 CPU usage, s total per block availability-recovery 52.630 17.543 Test environment 0.271 0.090 polkadot/node/subsystem-bench/examples/availability_read.yaml #3 Network usage, KiB total per block Received from peers 424379.000 141459.667 Sent to peers 703.000 234.333 CPU usage, s total per block availability-recovery 51.128 17.043 Test environment 0.502 0.167 ``` ``` $ cargo run -p polkadot-subsystem-bench --release -- --ci test-sequence --path polkadot/node/subsystem-bench/examples/availability_read.yaml | tee output.txt $ cat output.txt - benchmark_name: 'polkadot/node/subsystem-bench/examples/availability_read.yaml #1' network: - resource: Received from peers total: 509011.0 per_block: 169670.33333333334 - resource: Sent to peers total: 220.0 per_block: 73.33333333333333 cpu: - resource: availability-recovery total: 31.845848445 per_block: 10.615282815 - resource: Test environment total: 0.23582828799999941 per_block: 0.07860942933333313 - benchmark_name: 'polkadot/node/subsystem-bench/examples/availability_read.yaml #2' network: - resource: Received from peers total: 411738.0 per_block: 137246.0 - resource: Sent to peers total: 351.0 per_block: 117.0 cpu: - resource: availability-recovery total: 18.93596025099999 per_block: 6.31198675033333 - resource: Test environment total: 0.2541994199999979 per_block: 0.0847331399999993 - benchmark_name: 'polkadot/node/subsystem-bench/examples/availability_read.yaml #3' network: - resource: Received from peers total: 424548.0 per_block: 141516.0 - resource: Sent to peers total: 703.0 per_block: 234.33333333333334 cpu: - resource: availability-recovery total: 16.54178526900001 per_block: 5.513928423000003 - resource: Test environment total: 0.43960946299999537 per_block: 0.14653648766666513 ``` --------- Co-authored-by:Andrei Sandu <[email protected]>
-
- Feb 05, 2024
-
-
Alexandru Gheorghe authored
## Summary Built on top of the tooling and ideas introduced in https://github.com/paritytech/polkadot-sdk/pull/2528, this PR introduces a synthetic benchmark for measuring and assessing the performance characteristics of the approval-voting and approval-distribution subsystems. Currently this allows, us to simulate the behaviours of these systems based on the following dimensions: ``` TestConfiguration: # Test 1 - objective: !ApprovalsTest last_considered_tranche: 89 min_coalesce: 1 max_coalesce: 6 enable_assignments_v2: true send_till_tranche: 60 stop_when_approved: false coalesce_tranche_diff: 12 workdir_prefix: "/tmp" num_no_shows_per_candidate: 0 approval_distribution_expected_tof: 6.0 approval_distribution_cpu_ms: 3.0 approval_voting_cpu_ms: 4.30 n_validators: 500 n_cores: 100 n_included_candidates: 100 min_pov_size: 1120 max_pov_size: 5120 peer_bandwidth: 524288000000 bandwidth: 524288000000 latency: min_latency: secs: 0 nanos: 1000000 max_latency: secs: 0 nanos: 100000000 error: 0 num_blocks: 10 ``` ## The approach 1. We build a real overseer with the real implementations for approval-voting and approval-distribution subsystems. 2. For a given network size, for each validator we pre-computed all potential assignments and approvals it would send, because this a computation heavy operation this will be cached on a file on disk and be re-used if the generation parameters don't change. 3. The messages will be sent accordingly to the configured parameters and those are split into 3 main benchmarking scenarios. ## Benchmarking scenarios ### Best case scenario *approvals_throughput_best_case.yaml* It send to the approval-distribution only the minimum required tranche to gathered the needed_approvals, so that a candidate is approved. ### Behaviour in the presence of no-shows *approvals_no_shows.yaml* It sends the tranche needed to approve a candidate when we have a maximum of *num_no_shows_per_candidate* tranches with no-shows for each candidate. ### Maximum throughput *approvals_throughput.yaml* It sends all the tranches for each block and measures the used CPU and necessary network bandwidth. by the approval-voting and approval-distribution subsystem. ## How to run it ``` cargo run -p polkadot-subsystem-bench --release -- test-sequence --path polkadot/node/subsystem-bench/examples/approvals_throughput.yaml ``` ## Evaluating performance ### Use the real subsystems metrics If you follow the steps in https://github.com/paritytech/polkadot-sdk/tree/master/polkadot/node/subsystem-bench#install-grafana for installing locally prometheus and grafana, all real metrics for the `approval-distribution`, `approval-voting` and overseer are available. E.g: <img width="2149" alt="Screenshot 2023-12-05 at 11 07 46" src="https://github.com/paritytech/polkadot-sdk/assets/49718502/cb8ae2dd-178b-4922-bfa4-dc37e572ed38"> <img width="2551" alt="Screenshot 2023-12-05 at 11 09 42" src="https://github.com/paritytech/polkadot-sdk/assets/49718502/8b4542ba-88b9-46f9-9b70-cc345366081b"> <img width="2154" alt="Screenshot 2023-12-05 at 11 10 15" src="https://github.com/paritytech/polkadot-sdk/assets/49718502/b8874d8d-632e-443a-9840-14ad8e90c54f"> <img width="2535" alt="Screenshot 2023-12-05 at 11 10 52" src="https://github.com/paritytech/polkadot-sdk/assets/49718502/779a439f-fd18-4985-bb80-85d5afad78e2"> ### Profile with pyroscope 1. Setup pyroscope following the steps in https://github.com/paritytech/polkadot-sdk/tree/master/polkadot/node/subsystem-bench#install-pyroscope, then run any of the benchmark scenario with `--profile` as the arguments. 2. Open the pyroscope dashboard in grafana, e.g: <img width="2544" alt="Screenshot 2024-01-09 at 17 09 58" src="https://github.com/paritytech/polkadot-sdk/assets/49718502/58f50c99-a910-4d20-951a-8b16639303d9"> ### Useful logs 1. Network bandwidth requirements: ``` Payload bytes received from peers: 503993 KiB total, 50399 KiB/block Payload bytes sent to peers: 629971 KiB total, 62997 KiB/block ``` 2. Cpu usage by the approval-distribution/approval-voting subsystems. ``` approval-distribution CPU usage 84.061s approval-distribution CPU usage per block 8.406s approval-voting CPU usage 96.532s approval-voting CPU usage per block 9.653s ``` 3. Time passed until a given block is approved ``` Chain selection approved after 3500 ms hash=0x0101010101010101010101010101010101010101010101010101010101010101 Chain selection approved after 4500 ms hash=0x0202020202020202020202020202020202020202020202020202020202020202 ``` ### Using benchmark to quantify improvements from https://github.com/paritytech/polkadot-sdk/pull/1178 + https://github.com/paritytech/polkadot-sdk/pull/1191 Using a versi-node we compare the scenarios where all new optimisations are disabled with a scenarios where tranche0 assignments are sent in a single message and a conservative simulation where the coalescing of approvals gives us just 50% reduction in the number of messages we send. Overall, what we see is a speedup of around 30-40% in the time it takes to process the necessary messages and a 30-40% reduction in the necessary bandwidth. #### Best case scenario comparison(minimum required tranches sent). Unoptimised ``` Number of blocks: 10 Payload bytes received from peers: 53289 KiB total, 5328 KiB/block Payload bytes sent to peers: 52489 KiB total, 5248 KiB/block approval-distribution CPU usage 6.732s approval-distribution CPU usage per block 0.673s approval-voting CPU usage 9.523s approval-voting CPU usage per block 0.952s ``` vs Optimisation enabled ``` Number of blocks: 10 Payload bytes received from peers: 32141 KiB total, 3214 KiB/block Payload bytes sent to peers: 37314 KiB total, 3731 KiB/block approval-distribution CPU usage 4.658s approval-distribution CPU usage per block 0.466s approval-voting CPU usage 6.236s approval-voting CPU usage per block 0.624s ``` #### Worst case all tranches sent, very unlikely happens when sharding breaks. Unoptimised ``` Number of blocks: 10 Payload bytes received from peers: 746393 KiB total, 74639 KiB/block Payload bytes sent to peers: 729151 KiB total, 72915 KiB/block approval-distribution CPU usage 118.681s approval-distribution CPU usage per block 11.868s approval-voting CPU usage 124.118s approval-voting CPU usage per block 12.412s ``` vs optimised ``` Number of blocks: 10 Payload bytes received from peers: 503993 KiB total, 50399 KiB/block Payload bytes sent to peers: 629971 KiB total, 62997 KiB/block approval-distribution CPU usage 84.061s approval-distribution CPU usage per block 8.406s approval-voting CPU usage 96.532s approval-voting CPU usage per block 9.653s ``` ## TODOs [x] Polish implementation. [x] Use what we have so far to evaluate https://github.com/paritytech/polkadot-sdk/pull/1191 before merging. [x] List of features and additional dimensions we want to use for benchmarking. [x] Run benchmark on hardware similar with versi and kusama nodes. [ ] Add benchmark to be run in CI for catching regression in performance. [ ] Rebase on latest changes for network emulation. --------- Signed-off-by:
Andrei Sandu <[email protected]> Signed-off-by:
-
- Jan 30, 2024
-
-
Alexander Samusev authored
cc https://github.com/paritytech/ci_cd/issues/926 --------- Signed-off-by:
Liam Aharon <[email protected]> Co-authored-by:
Dónal Murray <[email protected]> Co-authored-by:
 Vladimir Istyufeev <[email protected]>
Vladimir Istyufeev <[email protected]>
-
- Jan 29, 2024
-
-
Alexandru Gheorghe authored
Pulls: https://github.com/paritytech/orchestra/pull/71 --------- Signed-off-by:
-
- Jan 26, 2024
-
-
Andrei Sandu authored
🤦🏼 --------- Signed-off-by:
-
- Jan 25, 2024
-
-
Andrei Sandu authored
Add subsystem benchmarks for `availability-distribution` and `biftield-distribution` (availability write) (#2970) Introduce a new test objective : `DataAvailabilityWrite`. The new benchmark measures the network and cpu usage of `availability-distribution`, `biftield-distribution` and `availability-store` subsystems from the perspective of a validator node during the process when candidates are made available. Additionally I refactored the networking emulation to support bandwidth acounting and limits of incoming and outgoing requests. Screenshot of succesful run <img width="1293" alt="Screenshot 2024-01-17 at 19 17 44" src="https://github.com/paritytech/polkadot-sdk/assets/54316454/fde11280-e25b-4dc3-9dc9-d4b9752f9b7a "> --------- Signed-off-by:
-
- Jan 21, 2024
-
-
s0me0ne-unkn0wn authored
This PR aims to channel the backpressure of the PVF host's preparation and execution queues to the candidate validation subsystem consumers. Related: #708
-
- Jan 18, 2024
-
-
dependabot[bot] authored
Bumps the known_good_semver group with 1 update: [clap](https://github.com/clap-rs/clap). Updates `clap` from 4.4.16 to 4.4.18 <details> <summary>Release notes</summary> <p><em>Sourced from <a href="https://github.com/clap-rs/clap/releases">clap's releases</a>.</em></p> <blockquote> <h2>v4.4.18</h2> <h2>[4.4.18] - 2024-01-16</h2> <h3>Fixes</h3> <ul> <li><em>(error)</em> When lacking <code>usage</code> feature, ensure the list of required arguments is unique</li> </ul> <h2>v4.4.17</h2> <h2>[4.4.17] - 2024-01-15</h2> <h3>Fixes</h3> <ul> <li>Fix <code>panic!</code> when mixing <code>args_conflicts_with_subcommands</code> with <code>ArgGroup</code> (which is implicit with <code>derive</code>) introduced in 4.4.15</li> </ul> </blockquote> </details> <details> <summary>Changelog</summary> <p><em>Sourced from <a href="https://github.com/clap-rs/clap/blob/master/CHANGELOG.md">clap's changelog</a>.</em></p> <blockquote> <h2>[4.4.18] - 2024-01-16</h2> <h3>Fixes</h3> <ul> <li><em>(error)</em> When lacking <code>usage</code> feature, ensure the list of required arguments is unique</li> </ul> <h2>[4.4.17] - 2024-01-15</h2> <h3>Fixes</h3> <ul> <li>Fix <code>panic!</code> when mixing <code>args_conflicts_with_subcommands</code> with <code>ArgGroup</code> (which is implicit with <code>derive</code>) introduced in 4.4.15</li> </ul> </blockquote> </details> <details> <summary>Commits</summary> <ul> <li><a href="https://github.com/clap-rs/clap/commit/0134f45ff0e2e2be8c451565e4fbf5d3cb7b7cfd"><code>0134f45</code></a> chore: Release</li> <li><a href="https://github.com/clap-rs/clap/commit/995ee032779d802606e599caf4f498ea51e92e82"><code>995ee03</code></a> docs: Update changelog</li> <li><a href="https://github.com/clap-rs/clap/commit/2f1890907ed4e78674feeb96df34cfb813b84686"><code>2f18909</code></a> Merge pull request <a href="https://redirect.github.com/clap-rs/clap/issues/5314">#5314</a> from epage/required</li> <li><a href="https://github.com/clap-rs/clap/commit/0a635b9a20077e2f932a9baee527052d8ed45d9e"><code>0a635b9</code></a> fix(parser): Don't duplicate requireds when usage disabled</li> <li><a href="https://github.com/clap-rs/clap/commit/e648e086f3934afb40b121b5999b9e23657ddc28"><code>e648e08</code></a> Merge pull request <a href="https://redirect.github.com/clap-rs/clap/issues/5311">#5311</a> from sourcefrog/doc-exitcode</li> <li><a href="https://github.com/clap-rs/clap/commit/8c83971b8c356b8c9abfbbb2320cb946a2ee8139"><code>8c83971</code></a> docs: Link to exit code info</li> <li><a href="https://github.com/clap-rs/clap/commit/b250c0b5f5920b59e551bf0ec90e17c6103ae4a2"><code>b250c0b</code></a> Merge pull request <a href="https://redirect.github.com/clap-rs/clap/issues/5310">#5310</a> from epage/pty</li> <li><a href="https://github.com/clap-rs/clap/commit/c742b8eb0ca648b645b616e064e00408944f390e"><code>c742b8e</code></a> chore(complete): Update completest-pty</li> <li><a href="https://github.com/clap-rs/clap/commit/f524d84c1d3eca1c980c5150c750d9e00cbbdb0c"><code>f524d84</code></a> chore: Release</li> <li><a href="https://github.com/clap-rs/clap/commit/944fb81cf593af1cd3a58dd959c934f0ff483182"><code>944fb81</code></a> docs: Update changelog</li> <li>Additional commits viewable in <a href="https://github.com/clap-rs/clap/compare/v4.4.16...v4.4.18">compare view</a></li> </ul> </details> <br /> [](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores ) Dependabot will resolve any conflicts with this PR as long as you don't alter it yourself. You can also trigger a rebase manually by commenting `@dependabot rebase`. [//]: # (dependabot-automerge-start) [//]: # (dependabot-automerge-end) --- <details> <summary>Dependabot commands and options</summary> <br /> You can trigger Dependabot actions by commenting on this PR: - `@dependabot rebase` will rebase this PR - `@dependabot recreate` will recreate this PR, overwriting any edits that have been made to it - `@dependabot merge` will merge this PR after your CI passes on it - `@dependabot squash and merge` will squash and merge this PR after your CI passes on it - `@dependabot cancel merge` will cancel a previously requested merge and block automerging - `@dependabot reopen` will reopen this PR if it is closed - `@dependabot close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually - `@dependabot show <dependency name> ignore conditions` will show all of the ignore conditions of the specified dependency - `@dependabot ignore <dependency name> major version` will close this group update PR and stop Dependabot creating any more for the specific dependency's major version (unless you unignore this specific dependency's major version or upgrade to it yourself) - `@dependabot ignore <dependency name> minor version` will close this group update PR and stop Dependabot creating any more for the specific dependency's minor version (unless you unignore this specific dependency's minor version or upgrade to it yourself) - `@dependabot ignore <dependency name>` will close this group update PR and stop Dependabot creating any more for the specific dependency (unless you unignore this specific dependency or upgrade to it yourself) - `@dependabot unignore <dependency name>` will remove all of the ignore conditions of the specified dependency - `@dependabot unignore <dependency name> <ignore condition>` will remove the ignore condition of the specified dependency and ignore conditions </details> Signed-off-by:
-
- Jan 16, 2024
-
-
Andrei Eres authored
## Why we need it To provide another level of understanding to why polkadot's subsystems may perform slower than expected. Cache misses occur when processing large amounts of data, such as during availability recovery. ## Why Cachegrind Cachegrind has many drawbacks: it is slow, it uses its own cache simulation, which is very basic. But unlike `perf`, which is a great tool, Cachegrind can run in a virtual machine. This means we can easily run it in remote installations and even use it in CI/CD to catch possible regressions. Why Cachegrind and not Callgrind, another part of Valgrind? It is simply empirically proven that profiling runs faster with Cachegrind. ## First results First results have been obtained while testing of the approach. Here is an example. ``` $ target/testnet/subsystem-bench --n-cores 10 --cache-misses data-availability-read $ cat cachegrind_report.txt I refs: 64,622,081,485 I1 misses: 3,018,168 LLi misses: 437,654 I1 miss rate: 0.00% LLi miss rate: 0.00% D refs: 12,161,833,115 (9,868,356,364 rd + 2,293,476,751 wr) D1 misses: 167,940,701 ( 71,060,073 rd + 96,880,628 wr) LLd misses: 33,550,018 ( 16,685,853 rd + 16,864,165 wr) D1 miss rate: 1.4% ( 0.7% + 4.2% ) LLd miss rate: 0.3% ( 0.2% + 0.7% ) LL refs: 170,958,869 ( 74,078,241 rd + 96,880,628 wr) LL misses: 33,987,672 ( 17,123,507 rd + 16,864,165 wr) LL miss rate: 0.0% ( 0.0% + 0.7% ) ``` The CLI output shows that 1.4% of the L1 data cache missed, which is not so bad, given that the last-level cache had that data most of the time missing only 0.3%. Instruction data of the L1 has 0.00% misses of the time. Looking at an output file with `cg_annotate` shows that most of the misses occur during reed-solomon, which is expected.
-
- Jan 15, 2024
-
-
dependabot[bot] authored
Bumps the known_good_semver group with 1 update: [clap](https://github.com/clap-rs/clap). Updates `clap` from 4.4.14 to 4.4.16 <details> <summary>Release notes</summary> <p><em>Sourced from <a href="https://github.com/clap-rs/clap/releases">clap's releases</a>.</em></p> <blockquote> <h2>v4.4.16</h2> <h2>[4.4.16] - 2024-01-12</h2> <h3>Fixes</h3> <ul> <li>Ensure invalid escape sequences in user-defined strings are correctly stripped when terminal doesn't support color</li> </ul> <h2>v4.4.15</h2> <h2>[4.4.15] - 2024-01-11</h2> <h3>Fixes</h3> <ul> <li>Improve error for <code>args_conflicts_with_subcommands</code></li> <li>Ensure we error for <code>args_conflicts_with_subcommands</code> when using subcommand short and long flags</li> </ul> </blockquote> </details> <details> <summary>Changelog</summary> <p><em>Sourced from <a href="https://github.com/clap-rs/clap/blob/master/CHANGELOG.md">clap's changelog</a>.</em></p> <blockquote> <h2>[4.4.16] - 2024-01-12</h2> <h3>Fixes</h3> <ul> <li>Ensure invalid escape sequences in user-defined strings are correctly stripped when terminal doesn't support color</li> </ul> <h2>[4.4.15] - 2024-01-11</h2> <h3>Fixes</h3> <ul> <li>Improve error for <code>args_conflicts_with_subcommands</code></li> <li>Ensure we error for <code>args_conflicts_with_subcommands</code> when using subcommand short and long flags</li> </ul> </blockquote> </details> <details> <summary>Commits</summary> <ul> <li><a href="https://github.com/clap-rs/clap/commit/cbc9c9dd44fc4be25c196213d508b9d2a9c282f3"><code>cbc9c9d</code></a> chore: Release</li> <li><a href="https://github.com/clap-rs/clap/commit/4718b89486c7c4236a18411b8449afc2d93f8e3d"><code>4718b89</code></a> docs: Update changelog</li> <li><a href="https://github.com/clap-rs/clap/commit/38f805cea0cf50a0f26ed01e4fdf550ca8a555fa"><code>38f805c</code></a> Merge pull request <a href="https://redirect.github.com/clap-rs/clap/issues/5299">#5299</a> from epage/ansi</li> <li><a href="https://github.com/clap-rs/clap/commit/2a3356a53543531726e851e97639810f3828a89b"><code>2a3356a</code></a> fix: Update anstream</li> <li><a href="https://github.com/clap-rs/clap/commit/12b5c39d467ea147c21f5eb3063fc0bc2538e9b7"><code>12b5c39</code></a> chore: Release</li> <li><a href="https://github.com/clap-rs/clap/commit/1c5b63390babdb4f3a8994436da4e7f9239b7d43"><code>1c5b633</code></a> docs: Update changelog</li> <li><a href="https://github.com/clap-rs/clap/commit/a5d46410e072b9821f76b21839849c4434a2f8da"><code>a5d4641</code></a> Merge pull request <a href="https://redirect.github.com/clap-rs/clap/issues/5298">#5298</a> from epage/conflict</li> <li><a href="https://github.com/clap-rs/clap/commit/f529ec398c4262296d5e6eb063b1b52d875d7f03"><code>f529ec3</code></a> fix(parser): Ensure subcommand flags can conflict</li> <li><a href="https://github.com/clap-rs/clap/commit/a7e04a53e4a9e310663a0cdb5bfb0753d84b82bd"><code>a7e04a5</code></a> fix(parser): Improve subcommand conflict error</li> <li><a href="https://github.com/clap-rs/clap/commit/ea00ef3051fd5a993b766062a4e9defc777bf233"><code>ea00ef3</code></a> refactor(error): Allow more conflict sources</li> <li>Additional commits viewable in <a href="https://github.com/clap-rs/clap/compare/v4.4.14...v4.4.16">compare view</a></li> </ul> </details> <br /> [](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores ) Dependabot will resolve any conflicts with this PR as long as you don't alter it yourself. You can also trigger a rebase manually by commenting `@dependabot rebase`. [//]: # (dependabot-automerge-start) [//]: # (dependabot-automerge-end) --- <details> <summary>Dependabot commands and options</summary> <br /> You can trigger Dependabot actions by commenting on this PR: - `@dependabot rebase` will rebase this PR - `@dependabot recreate` will recreate this PR, overwriting any edits that have been made to it - `@dependabot merge` will merge this PR after your CI passes on it - `@dependabot squash and merge` will squash and merge this PR after your CI passes on it - `@dependabot cancel merge` will cancel a previously requested merge and block automerging - `@dependabot reopen` will reopen this PR if it is closed - `@dependabot close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually - `@dependabot show <dependency name> ignore conditions` will show all of the ignore conditions of the specified dependency - `@dependabot ignore <dependency name> major version` will close this group update PR and stop Dependabot creating any more for the specific dependency's major version (unless you unignore this specific dependency's major version or upgrade to it yourself) - `@dependabot ignore <dependency name> minor version` will close this group update PR and stop Dependabot creating any more for the specific dependency's minor version (unless you unignore this specific dependency's minor version or upgrade to it yourself) - `@dependabot ignore <dependency name>` will close this group update PR and stop Dependabot creating any more for the specific dependency (unless you unignore this specific dependency or upgrade to it yourself) - `@dependabot unignore <dependency name>` will remove all of the ignore conditions of the specified dependency - `@dependabot unignore <dependency name> <ignore condition>` will remove the ignore condition of the specified dependency and ignore conditions </details> Signed-off-by:
-
- Jan 10, 2024
-
-
Alin Dima authored
Previously, it was only possible to retry the same request on a different protocol name that had the exact same binary payloads. Introduce a way of trying a different request on a different protocol if the first one fails with Unsupported protocol. This helps with adding new req-response versions in polkadot while preserving compatibility with unupgraded nodes. The way req-response protocols were bumped previously was that they were bundled with some other notifications protocol upgrade, like for async backing (but that is more complicated, especially if the feature does not require any changes to a notifications protocol). Will be needed for implementing https://github.com/polkadot-fellows/RFCs/pull/47 TODO: - [x] add tests - [x] add guidance docs in polkadot about req-response protocol versioning
-
- Jan 09, 2024
-
-
dependabot[bot] authored
Bumps the known_good_semver group with 1 update: [clap](https://github.com/clap-rs/clap). Updates `clap` from 4.4.13 to 4.4.14 <details> <summary>Release notes</summary> <p><em>Sourced from <a href="https://github.com/clap-rs/clap/releases">clap's releases</a>.</em></p> <blockquote> <h2>v4.4.14</h2> <h2>[4.4.14] - 2024-01-08</h2> <h3>Documentation</h3> <ul> <li>Fix <code>find</code> cookbook entry to allow repeats of flags/options</li> </ul> <h3>Features</h3> <ul> <li>Allow <code>num_args(0)</code> on options which allows making them emulate being a flag for position-tracking flags</li> </ul> </blockquote> </details> <details> <summary>Changelog</summary> <p><em>Sourced from <a href="https://github.com/clap-rs/clap/blob/master/CHANGELOG.md">clap's changelog</a>.</em></p> <blockquote> <h2>[4.4.14] - 2024-01-08</h2> <h3>Documentation</h3> <ul> <li>Fix <code>find</code> cookbook entry to allow repeats of flags/options</li> </ul> <h3>Features</h3> <ul> <li>Allow <code>num_args(0)</code> on options which allows making them emulate being a flag for position-tracking flags</li> </ul> </blockquote> </details> <details> <summary>Commits</summary> <ul> <li><a href="https://github.com/clap-rs/clap/commit/514f28bc92ed683d53292cbe9457db3ec5df7b6f"><code>514f28b</code></a> chore: Release</li> <li><a href="https://github.com/clap-rs/clap/commit/1440456d3ddaa6d9624297d83de9bb9abe82f10b"><code>1440456</code></a> docs: Update changelog</li> <li><a href="https://github.com/clap-rs/clap/commit/d6479ff7ddbcf524146428c92be23273b4f8bac5"><code>d6479ff</code></a> Merge pull request <a href="https://redirect.github.com/clap-rs/clap/issues/5290">#5290</a> from epage/or</li> <li><a href="https://github.com/clap-rs/clap/commit/02f82146ad746ce9d1874e38ec7033150bb12622"><code>02f8214</code></a> docs(cookbook): Clarify intent of fake flags</li> <li><a href="https://github.com/clap-rs/clap/commit/c603f34574832b8894b44e0f67fd19dc7869e808"><code>c603f34</code></a> Merge pull request <a href="https://redirect.github.com/clap-rs/clap/issues/5275">#5275</a> from epage/ci</li> <li><a href="https://github.com/clap-rs/clap/commit/641b42b2e82086775619bd15854ddb5b80311b49"><code>641b42b</code></a> chore(ci): Speed up critical path of CI</li> <li><a href="https://github.com/clap-rs/clap/commit/3eaf1af052bd5255cc2440dc1cc8f80831a3428b"><code>3eaf1af</code></a> fix(help): Correctly show help for fake flags</li> <li><a href="https://github.com/clap-rs/clap/commit/d63106b9f698df0d2241662ab1459c823890dec4"><code>d63106b</code></a> docs(cookbook): Allow repeated operators</li> <li><a href="https://github.com/clap-rs/clap/commit/148e102ac37bd0e5ca99cfe9c5d57ffc6243cf66"><code>148e102</code></a> fix(builder): Allow custom flag definitions</li> <li><a href="https://github.com/clap-rs/clap/commit/d53d881e339fec64e48990170b542fae4140eaaa"><code>d53d881</code></a> docs(cookbook): Demonstrate bad 'find' behavior</li> <li>See full diff in <a href="https://github.com/clap-rs/clap/compare/v4.4.13...v4.4.14">compare view</a></li> </ul> </details> <br /> [](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores ) Dependabot will resolve any conflicts with this PR as long as you don't alter it yourself. You can also trigger a rebase manually by commenting `@dependabot rebase`. [//]: # (dependabot-automerge-start) [//]: # (dependabot-automerge-end) --- <details> <summary>Dependabot commands and options</summary> <br /> You can trigger Dependabot actions by commenting on this PR: - `@dependabot rebase` will rebase this PR - `@dependabot recreate` will recreate this PR, overwriting any edits that have been made to it - `@dependabot merge` will merge this PR after your CI passes on it - `@dependabot squash and merge` will squash and merge this PR after your CI passes on it - `@dependabot cancel merge` will cancel a previously requested merge and block automerging - `@dependabot reopen` will reopen this PR if it is closed - `@dependabot close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually - `@dependabot show <dependency name> ignore conditions` will show all of the ignore conditions of the specified dependency - `@dependabot ignore <dependency name> major version` will close this group update PR and stop Dependabot creating any more for the specific dependency's major version (unless you unignore this specific dependency's major version or upgrade to it yourself) - `@dependabot ignore <dependency name> minor version` will close this group update PR and stop Dependabot creating any more for the specific dependency's minor version (unless you unignore this specific dependency's minor version or upgrade to it yourself) - `@dependabot ignore <dependency name>` will close this group update PR and stop Dependabot creating any more for the specific dependency (unless you unignore this specific dependency or upgrade to it yourself) - `@dependabot unignore <dependency name>` will remove all of the ignore conditions of the specified dependency - `@dependabot unignore <dependency name> <ignore condition>` will remove the ignore condition of the specified dependency and ignore conditions </details> Signed-off-by:
-
- Jan 07, 2024
-
-
dependabot[bot] authored
Bumps the known_good_semver group with 4 updates: [serde](https://github.com/serde-rs/serde), [serde_json](https://github.com/serde-rs/json), [clap](https://github.com/clap-rs/clap) and [syn](https://github.com/dtolnay/syn). Updates `serde` from 1.0.194 to 1.0.195 <details> <summary>Release notes</summary> <p><em>Sourced from <a href="https://github.com/serde-rs/serde/releases">serde's releases</a>.</em></p> <blockquote> <h2>v1.0.195</h2> <ul> <li>Prevent remote definitions of tuple struct or tuple variant from triggering dead_code warning (<a href="https://redirect.github.com/serde-rs/serde/issues/2671">#2671</a>)</li> </ul> </blockquote> </details> <details> <summary>Commits</summary> <ul> <li><a href="https://github.com/serde-rs/serde/commit/03eec42c3313b36da416be1486e9ecac345784d5"><code>03eec42</code></a> Release 1.0.195</li> <li><a href="https://github.com/serde-rs/serde/commit/196f311ae2fd8ad94fe38a57830419859a4d3dbb"><code>196f311</code></a> Merge pull request <a href="https://redirect.github.com/serde-rs/serde/issues/2671">#2671</a> from dtolnay/deadremote</li> <li><a href="https://github.com/serde-rs/serde/commit/38d9e0b2091e9b6150486c2c37367819b86bcc39"><code>38d9e0b</code></a> Revert "Add FIXME to fix dead_code warning when using serde(remote)"</li> <li><a href="https://github.com/serde-rs/serde/commit/6502b3131697eff6420786ad71f87f29cfff3a13"><code>6502b31</code></a> Fix new dead_code warning in tuple struct and tuple variant remote defs</li> <li><a href="https://github.com/serde-rs/serde/commit/6f1a8c3115c8d2502178c25d610fbaee2e82c46b"><code>6f1a8c3</code></a> Add FIXME to fix dead_code warning when using serde(remote)</li> <li><a href="https://github.com/serde-rs/serde/commit/d883c94cc9fe72d0512dc7f4def7191a401595c9"><code>d883c94</code></a> Work around dead_code warning in tests</li> <li><a href="https://github.com/serde-rs/serde/commit/961fa59a7469c5b5e323b9723323df412048d60d"><code>961fa59</code></a> Merge pull request <a href="https://redirect.github.com/serde-rs/serde/issues/2670">#2670</a> from serde-rs/exhaustive</li> <li><a href="https://github.com/serde-rs/serde/commit/8bc71def551df190e6817d3311e5c76f751f53e6"><code>8bc71de</code></a> Fill in omitted patterns for GenericArguments match</li> <li><a href="https://github.com/serde-rs/serde/commit/7c65a9dc0eab2d4d829b258a7b3549351bbe8dcd"><code>7c65a9d</code></a> Pick up changes to non_exhaustive_omitted_patterns lint</li> <li>See full diff in <a href="https://github.com/serde-rs/serde/compare/v1.0.194...v1.0.195">compare view</a></li> </ul> </details> <br /> Updates `serde_json` from 1.0.110 to 1.0.111 <details> <summary>Release notes</summary> <p><em>Sourced from <a href="https://github.com/serde-rs/json/releases">serde_json's releases</a>.</em></p> <blockquote> <h2>v1.0.111</h2> <ul> <li>Improve floating point parsing performance on loongarch64 (<a href="https://redirect.github.com/serde-rs/json/issues/1100">#1100</a>, thanks <a href="https://github.com/heiher"><code>@heiher</code></a>)</li> </ul> </blockquote> </details> <details> <summary>Commits</summary> <ul> <li><a href="https://github.com/serde-rs/json/commit/0131ac68212e8094bd14ee618587d731b4f9a68b"><code>0131ac6</code></a> Release 1.0.111</li> <li><a href="https://github.com/serde-rs/json/commit/96ecfadd3f7dd6366a2d07a098e228d15df93cb4"><code>96ecfad</code></a> Merge pull request <a href="https://redirect.github.com/serde-rs/json/issues/1100">#1100</a> from heiher/limb-64-la64</li> <li><a href="https://github.com/serde-rs/json/commit/c80dbaf8ff5902ca670e0a48bbe495065b9314f5"><code>c80dbaf</code></a> Set limb width to 64 for loongarch64</li> <li>See full diff in <a href="https://github.com/serde-rs/json/compare/v1.0.110...v1.0.111">compare view</a></li> </ul> </details> <br /> Updates `clap` from 4.4.12 to 4.4.13 <details> <summary>Release notes</summary> <p><em>Sourced from <a href="https://github.com/clap-rs/clap/releases">clap's releases</a>.</em></p> <blockquote> <h2>v4.4.13</h2> <h2>[4.4.13] - 2024-01-04</h2> <h3>Documentation</h3> <ul> <li>Fix link to structopt migration guide</li> </ul> </blockquote> </details> <details> <summary>Changelog</summary> <p><em>Sourced from <a href="https://github.com/clap-rs/clap/blob/master/CHANGELOG.md">clap's changelog</a>.</em></p> <blockquote> <h2>[4.4.13] - 2024-01-04</h2> <h3>Documentation</h3> <ul> <li>Fix link to structopt migration guide</li> </ul> </blockquote> </details> <details> <summary>Commits</summary> <ul> <li><a href="https://github.com/clap-rs/clap/commit/2ab48b295c2463ce8c141a9868095b811ccf3b99"><code>2ab48b2</code></a> chore: Release</li> <li><a href="https://github.com/clap-rs/clap/commit/7a06a8cd619db704c6d826bf752eae3b86ce23a8"><code>7a06a8c</code></a> docs: Update changelog</li> <li><a href="https://github.com/clap-rs/clap/commit/cca190efedf40f48147a3a4a777a9cc17728abdf"><code>cca190e</code></a> docs: Correct link to StructOpt migration guide</li> <li><a href="https://github.com/clap-rs/clap/commit/5c31f453c1a9f46109db8e0a47ed212748c0556c"><code>5c31f45</code></a> Merge pull request <a href="https://redirect.github.com/clap-rs/clap/issues/5281">#5281</a> from Manishearth/safety-docs</li> <li><a href="https://github.com/clap-rs/clap/commit/ddae7e6f411c4c87294212152b8d9beea16637e7"><code>ddae7e6</code></a> Correct safety docs</li> <li><a href="https://github.com/clap-rs/clap/commit/48d28aa689bfd0fb44ec025244b30ba261e2515a"><code>48d28aa</code></a> chore: Release</li> <li><a href="https://github.com/clap-rs/clap/commit/748ce18cc2ccc3f7c07fa8b7c5b6f90ed9242b72"><code>748ce18</code></a> docs: Update changelog</li> <li><a href="https://github.com/clap-rs/clap/commit/adbe6ec4cb6a617070c41927a389d0bea7b30936"><code>adbe6ec</code></a> Merge pull request <a href="https://redirect.github.com/clap-rs/clap/issues/5278">#5278</a> from henry-hsieh/fix-nosort</li> <li><a href="https://github.com/clap-rs/clap/commit/2b48858ba84c62e9af97bee4734d70530254cd8a"><code>2b48858</code></a> fix: Skip nosort option below bash 4.4</li> <li><a href="https://github.com/clap-rs/clap/commit/777b744102cde324dc75534ef043efc15a9f40be"><code>777b744</code></a> Merge pull request <a href="https://redirect.github.com/clap-rs/clap/issues/5277">#5277</a> from clap-rs/renovate/actions-setup-python-5.x</li> <li>Additional commits viewable in <a href="https://github.com/clap-rs/clap/compare/v4.4.12...v4.4.13">compare view</a></li> </ul> </details> <br /> Updates `syn` from 2.0.47 to 2.0.48 <details> <summary>Release notes</summary> <p><em>Sourced from <a href="https://github.com/dtolnay/syn/releases">syn's releases</a>.</em></p> <blockquote> <h2>2.0.48</h2> <ul> <li>Improve error message on unexpected token after <code>else</code> (<a href="https://redirect.github.com/dtolnay/syn/issues/1578">#1578</a>)</li> </ul> </blockquote> </details> <details> <summary>Commits</summary> <ul> <li><a href="https://github.com/dtolnay/syn/commit/5e16fc24e68b16a381cb7ef22455dba9db143083"><code>5e16fc2</code></a> Release 2.0.48</li> <li><a href="https://github.com/dtolnay/syn/commit/dc40084b15ab4a443179fc39cbadac6452408838"><code>dc40084</code></a> Merge pull request <a href="https://redirect.github.com/dtolnay/syn/issues/1578">#1578</a> from dtolnay/elseblock</li> <li><a href="https://github.com/dtolnay/syn/commit/82fcefce69d36e78301936c5af91f005d6a24357"><code>82fcefc</code></a> Fix error message on unexpected token after 'else'</li> <li><a href="https://github.com/dtolnay/syn/commit/e8a5c68ad45194e575a923f6b1e08f1817196331"><code>e8a5c68</code></a> Merge pull request <a href="https://redirect.github.com/dtolnay/syn/issues/1576">#1576</a> from dtolnay/exhaustive</li> <li><a href="https://github.com/dtolnay/syn/commit/97b1df6d935cb4801f4090782304577c8574d024"><code>97b1df6</code></a> Pick up changes to non_exhaustive_omitted_patterns lint</li> <li>See full diff in <a href="https://github.com/dtolnay/syn/compare/2.0.47...2.0.48 ">compare view</a></li> </ul> </details> <br /> Dependabot will resolve any conflicts with this PR as long as you don't alter it yourself. You can also trigger a rebase manually by commenting `@dependabot rebase`. [//]: # (dependabot-automerge-start) [//]: # (dependabot-automerge-end) --- <details> <summary>Dependabot commands and options</summary> <br /> You can trigger Dependabot actions by commenting on this PR: - `@dependabot rebase` will rebase this PR - `@dependabot recreate` will recreate this PR, overwriting any edits that have been made to it - `@dependabot merge` will merge this PR after your CI passes on it - `@dependabot squash and merge` will squash and merge this PR after your CI passes on it - `@dependabot cancel merge` will cancel a previously requested merge and block automerging - `@dependabot reopen` will reopen this PR if it is closed - `@dependabot close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually - `@dependabot show <dependency name> ignore conditions` will show all of the ignore conditions of the specified dependency - `@dependabot ignore <dependency name> major version` will close this group update PR and stop Dependabot creating any more for the specific dependency's major version (unless you unignore this specific dependency's major version or upgrade to it yourself) - `@dependabot ignore <dependency name> minor version` will close this group update PR and stop Dependabot creating any more for the specific dependency's minor version (unless you unignore this specific dependency's minor version or upgrade to it yourself) - `@dependabot ignore <dependency name>` will close this group update PR and stop Dependabot creating any more for the specific dependency (unless you unignore this specific dependency or upgrade to it yourself) - `@dependabot unignore <dependency name>` will remove all of the ignore conditions of the specified dependency - `@dependabot unignore <dependency name> <ignore condition>` will remove the ignore condition of the specified dependency and ignore conditions </details> Signed-off-by:
-
- Jan 05, 2024
-
-
Tsvetomir Dimitrov authored
Fix some issues reported by clippy
-
- Jan 04, 2024
-
-
dependabot[bot] authored
Bumps the known_good_semver group with 4 updates: [serde](https://github.com/serde-rs/serde), [serde_json](https://github.com/serde-rs/json), [clap](https://github.com/clap-rs/clap) and [serde_yaml](https://github.com/dtolnay/serde-yaml). Updates `serde` from 1.0.193 to 1.0.194 <details> <summary>Release notes</summary> <p><em>Sourced from <a href="https://github.com/serde-rs/serde/releases">serde's releases</a>.</em></p> <blockquote> <h2>v1.0.194</h2> <ul> <li>Update proc-macro2 to fix caching issue when using a rustc-wrapper such as sccache</li> </ul> </blockquote> </details> <details> <summary>Commits</summary> <ul> <li><a href="https://github.com/serde-rs/serde/commit/d2d977a6c6dcff237ae956336d18b0c900c61aad"><code>d2d977a</code></a> Release 1.0.194</li> <li><a href="https://github.com/serde-rs/serde/commit/a9a6ee9d7f2e3a3306ad7c7a8f21dcf369c6acb7"><code>a9a6ee9</code></a> Pull in proc-macro2 sccache fix</li> <li><a href="https://github.com/serde-rs/serde/commit/28c5d215c11b66368b725f04cb92e49e4350bcdc"><code>28c5d21</code></a> Merge pull request <a href="https://redirect.github.com/serde-rs/serde/issues/2669">#2669</a> from dtolnay/optionifletelse</li> <li><a href="https://github.com/serde-rs/serde/commit/3d6a789562579fb7ea783e0d7f35530914d8baca"><code>3d6a789</code></a> Remove option_if_let_else clippy suppression</li> <li><a href="https://github.com/serde-rs/serde/commit/a0e68698e33fa928f1d9f208d68b17df9f8bb568"><code>a0e6869</code></a> Work around doc_link_with_quotes pedantic clippy lint</li> <li>See full diff in <a href="https://github.com/serde-rs/serde/compare/v1.0.193...v1.0.194">compare view</a></li> </ul> </details> <br /> Updates `serde_json` from 1.0.108 to 1.0.110 <details> <summary>Release notes</summary> <p><em>Sourced from <a href="https://github.com/serde-rs/json/releases">serde_json's releases</a>.</em></p> <blockquote> <h2>v1.0.109</h2> <ul> <li>Documentation improvements</li> </ul> </blockquote> </details> <details> <summary>Commits</summary> <ul> <li><a href="https://github.com/serde-rs/json/commit/df5cf215b70fb6341b255e7c0a210c06f64c0669"><code>df5cf21</code></a> Release 1.0.110</li> <li><a href="https://github.com/serde-rs/json/commit/c35856a93c37b48b3d6efc4fec8e05554dd3f9d5"><code>c35856a</code></a> Pull in proc-macro2 sccache fix</li> <li><a href="https://github.com/serde-rs/json/commit/f88bf1fccb05aa4de129675de44eb6aaf3fec0a0"><code>f88bf1f</code></a> Release 1.0.109</li> <li><a href="https://github.com/serde-rs/json/commit/bb62c73ecef901e689b0a7a67ed613a32975520c"><code>bb62c73</code></a> Merge pull request <a href="https://redirect.github.com/serde-rs/json/issues/1097">#1097</a> from serde-rs/doccfg</li> <li><a href="https://github.com/serde-rs/json/commit/df36d109fd9f9cdd22a874c0177cafec12237f95"><code>df36d10</code></a> Restore doc cfg on re-exports</li> <li><a href="https://github.com/serde-rs/json/commit/c3670913423329c166add9d85ecdfc3e3da21e7a"><code>c367091</code></a> Merge pull request <a href="https://redirect.github.com/serde-rs/json/issues/1095">#1095</a> from dtolnay/hashtest</li> <li><a href="https://github.com/serde-rs/json/commit/b328ee7df4dd772922f084600aa7cea39218b694"><code>b328ee7</code></a> Eliminate hash closure in favor of calling hash_one directly</li> <li><a href="https://github.com/serde-rs/json/commit/b9bcbad3c094042f79f1a45189ec0edbb8f9f322"><code>b9bcbad</code></a> Use BuildHasher::hash_one</li> <li><a href="https://github.com/serde-rs/json/commit/7ff6c9e30c2ecc2cdcf089ed86c7ccfe7a41721c"><code>7ff6c9e</code></a> Use random hasher state for number hashing test</li> <li><a href="https://github.com/serde-rs/json/commit/fe031cd1de4dde5b47e0f18934632b41bd18b48d"><code>fe031cd</code></a> Delete trace_macros! functionality from test</li> <li>Additional commits viewable in <a href="https://github.com/serde-rs/json/compare/v1.0.108...v1.0.110">compare view</a></li> </ul> </details> <br /> Updates `clap` from 4.4.11 to 4.4.12 <details> <summary>Release notes</summary> <p><em>Sourced from <a href="https://github.com/clap-rs/clap/releases">clap's releases</a>.</em></p> <blockquote> <h2>v4.4.12</h2> <h2>[4.4.12] - 2023-12-28</h2> <h3>Performance</h3> <ul> <li>Only ask <code>TypedValueParser</code> for possible values if needed</li> </ul> </blockquote> </details> <details> <summary>Changelog</summary> <p><em>Sourced from <a href="https://github.com/clap-rs/clap/blob/master/CHANGELOG.md">clap's changelog</a>.</em></p> <blockquote> <h2>[4.4.12] - 2023-12-28</h2> <h3>Performance</h3> <ul> <li>Only ask <code>TypedValueParser</code> for possible values if needed</li> </ul> </blockquote> </details> <details> <summary>Commits</summary> <ul> <li><a href="https://github.com/clap-rs/clap/commit/6d601e6f312857d78f47741268f1748840484d4a"><code>6d601e6</code></a> chore: Release</li> <li><a href="https://github.com/clap-rs/clap/commit/048e7f0fbc4f8108894e4307af768c8d332a0576"><code>048e7f0</code></a> docs: Update changelog</li> <li><a href="https://github.com/clap-rs/clap/commit/53f5b820988c1c03f0d2696fc144857ad461edc1"><code>53f5b82</code></a> Merge pull request <a href="https://redirect.github.com/clap-rs/clap/issues/5267">#5267</a> from vermiculus/sa/avoid-pv-expansion-in-help</li> <li><a href="https://github.com/clap-rs/clap/commit/05cd057978db743a65fb5fde33213af752d064e7"><code>05cd057</code></a> perf: Avoid retrieving possible_values unless used</li> <li><a href="https://github.com/clap-rs/clap/commit/29208083b0598ba7d1b80e79821c0ba3eb2342ce"><code>2920808</code></a> test: Update snapshots</li> <li><a href="https://github.com/clap-rs/clap/commit/28763ebb6d8714f6ca588bf477729040e0e760b0"><code>28763eb</code></a> chore: Release</li> <li><a href="https://github.com/clap-rs/clap/commit/ace7bb5b4570b030f7c2d0fa91e0afaaac1b0030"><code>ace7bb5</code></a> docs(complete): Update changelog</li> <li><a href="https://github.com/clap-rs/clap/commit/76beca4d4d42a817bbb578f23553c64ded2aea97"><code>76beca4</code></a> docs(complete): Polish API reference for dynamic</li> <li><a href="https://github.com/clap-rs/clap/commit/3630e582d3ec59912b8e9369c38687695ddb1f43"><code>3630e58</code></a> Merge pull request <a href="https://redirect.github.com/clap-rs/clap/issues/5273">#5273</a> from epage/docsrs</li> <li><a href="https://github.com/clap-rs/clap/commit/3724b9e2e4c2a2e69337b6d809949b246d3fef39"><code>3724b9e</code></a> docs: Include more content on docs.rs</li> <li>See full diff in <a href="https://github.com/clap-rs/clap/compare/v4.4.11...v4.4.12">compare view</a></li> </ul> </details> <br /> Updates `serde_yaml` from 0.9.29 to 0.9.30 <details> <summary>Release notes</summary> <p><em>Sourced from <a href="https://github.com/dtolnay/serde-yaml/releases">serde_yaml's releases</a>.</em></p> <blockquote> <h2>0.9.30</h2> <ul> <li>Update proc-macro2 to fix caching issue when using a rustc-wrapper such as sccache</li> </ul> </blockquote> </details> <details> <summary>Commits</summary> <ul> <li><a href="https://github.com/dtolnay/serde-yaml/commit/09ee25156f608f95150b27edd120bd5471db3c64"><code>09ee251</code></a> Release 0.9.30</li> <li><a href="https://github.com/dtolnay/serde-yaml/commit/caea939ece85ab54ac41de0672d683905f1e406a"><code>caea939</code></a> Pull in proc-macro2 sccache fix</li> <li><a href="https://github.com/dtolnay/serde-yaml/commit/d255918c141fd72d01f169bb5aa0152234981699"><code>d255918</code></a> Merge pull request <a href="https://redirect.github.com/dtolnay/serde-yaml/issues/403">#403</a> from dtolnay/optionifletelse</li> <li><a href="https://github.com/dtolnay/serde-yaml/commit/8cfeedd766f83dab24d03b9fb11b72886a247425"><code>8cfeedd</code></a> Remove option_if_let_else clippy suppression</li> <li>See full diff in <a href="https://github.com/dtolnay/serde-yaml/compare/0.9.29...0.9.30 ">compare view</a></li> </ul> </details> <br /> Dependabot will resolve any conflicts with this PR as long as you don't alter it yourself. You can also trigger a rebase manually by commenting `@dependabot rebase`. [//]: # (dependabot-automerge-start) [//]: # (dependabot-automerge-end) --- <details> <summary>Dependabot commands and options</summary> <br /> You can trigger Dependabot actions by commenting on this PR: - `@dependabot rebase` will rebase this PR - `@dependabot recreate` will recreate this PR, overwriting any edits that have been made to it - `@dependabot merge` will merge this PR after your CI passes on it - `@dependabot squash and merge` will squash and merge this PR after your CI passes on it - `@dependabot cancel merge` will cancel a previously requested merge and block automerging - `@dependabot reopen` will reopen this PR if it is closed - `@dependabot close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually - `@dependabot show <dependency name> ignore conditions` will show all of the ignore conditions of the specified dependency - `@dependabot ignore <dependency name> major version` will close this group update PR and stop Dependabot creating any more for the specific dependency's major version (unless you unignore this specific dependency's major version or upgrade to it yourself) - `@dependabot ignore <dependency name> minor version` will close this group update PR and stop Dependabot creating any more for the specific dependency's minor version (unless you unignore this specific dependency's minor version or upgrade to it yourself) - `@dependabot ignore <dependency name>` will close this group update PR and stop Dependabot creating any more for the specific dependency (unless you unignore this specific dependency or upgrade to it yourself) - `@dependabot unignore <dependency name>` will remove all of the ignore conditions of the specified dependency - `@dependabot unignore <dependency name> <ignore condition>` will remove the ignore condition of the specified dependency and ignore conditions </details> Signed-off-by:
-
- Dec 19, 2023
-
-
Andrei Eres authored
Ready-to-merge version of https://github.com/paritytech/polkadot-sdk/pull/2601 - Added optional CPU profiling - Updated instructions how to set up Prometheus, Pyroscope and Graphana - Added a flamegraph dashboard <img width="1470" alt="image" src="https://github.com/paritytech/polkadot-sdk/assets/27277055/c8f3b33d-3c01-4ec0-ac34-72d52325b6e6 "> --------- Co-authored-by:
-
- Dec 18, 2023
-
-
dependabot[bot] authored
Bumps [async-trait](https://github.com/dtolnay/async-trait) from 0.1.73 to 0.1.74. <details> <summary>Release notes</summary> <p><em>Sourced from <a href="https://github.com/dtolnay/async-trait/releases">async-trait's releases</a>.</em></p> <blockquote> <h2>0.1.74</h2> <ul> <li>Documentation improvements</li> </ul> </blockquote> </details> <details> <summary>Commits</summary> <ul> <li><a href="https://github.com/dtolnay/async-trait/commit/265979b07a9af573e1edd3b2a9b179533cfa7a6c"><code>265979b</code></a> Release 0.1.74</li> <li><a href="https://github.com/dtolnay/async-trait/commit/5e677097d2e67f7a5c5e3023e2f3b99b36a9e132"><code>5e67709</code></a> Fix doc test when async fn in trait is natively supported</li> <li><a href="https://github.com/dtolnay/async-trait/commit/ef144aed28b636eb65759505b2323afc4c753fbe"><code>ef144ae</code></a> Update ui test suite to nightly-2023-10-15</li> <li><a href="https://github.com/dtolnay/async-trait/commit/9398a28d6fc977ccf8c286bd85b4b87a883f92ac"><code>9398a28</code></a> Test docs.rs documentation build in CI</li> <li><a href="https://github.com/dtolnay/async-trait/commit/8737173dafa371e5e9e491d736513be1baf697f4"><code>8737173</code></a> Update ui test suite to nightly-2023-09-24</li> <li><a href="https://github.com/dtolnay/async-trait/commit/5ba643c001a55f70c4a44690e040cdfab873ba56"><code>5ba643c</code></a> Test dyn Trait containing async fn</li> <li><a href="https://github.com/dtolnay/async-trait/commit/247c8e7b0b3ff69c9518ebf93e69fe74d47f17b6"><code>247c8e7</code></a> Add ui test testing the recommendation to use async-trait</li> <li><a href="https://github.com/dtolnay/async-trait/commit/799db66a84834c403860df4a8c0227d8fb7f9d9d"><code>799db66</code></a> Update ui test suite to nightly-2023-09-23</li> <li><a href="https://github.com/dtolnay/async-trait/commit/0e60248011f751d8ccf58219d0a79aacfe9619f1"><code>0e60248</code></a> Update actions/checkout@v3 -> v4</li> <li><a href="https://github.com/dtolnay/async-trait/commit/7fcbc83993d5ef483d048c271a7f6c4ac8c98388"><code>7fcbc83</code></a> Update ui test suite to nightly-2023-08-29</li> <li>See full diff in <a href="https://github.com/dtolnay/async-trait/compare/0.1.73...0.1.74">compare view</a></li> </ul> </details> <br /> [](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores ) Dependabot will resolve any conflicts with this PR as long as you don't alter it yourself. You can also trigger a rebase manually by commenting `@dependabot rebase`. [//]: # (dependabot-automerge-start) [//]: # (dependabot-automerge-end) --- <details> <summary>Dependabot commands and options</summary> <br /> You can trigger Dependabot actions by commenting on this PR: - `@dependabot rebase` will rebase this PR - `@dependabot recreate` will recreate this PR, overwriting any edits that have been made to it - `@dependabot merge` will merge this PR after your CI passes on it - `@dependabot squash and merge` will squash and merge this PR after your CI passes on it - `@dependabot cancel merge` will cancel a previously requested merge and block automerging - `@dependabot reopen` will reopen this PR if it is closed - `@dependabot close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually - `@dependabot show <dependency name> ignore conditions` will show all of the ignore conditions of the specified dependency - `@dependabot ignore <dependency name> major version` will close this group update PR and stop Dependabot creating any more for the specific dependency's major version (unless you unignore this specific dependency's major version or upgrade to it yourself) - `@dependabot ignore <dependency name> minor version` will close this group update PR and stop Dependabot creating any more for the specific dependency's minor version (unless you unignore this specific dependency's minor version or upgrade to it yourself) - `@dependabot ignore <dependency name>` will close this group update PR and stop Dependabot creating any more for the specific dependency (unless you unignore this specific dependency or upgrade to it yourself) - `@dependabot unignore <dependency name>` will remove all of the ignore conditions of the specified dependency - `@dependabot unignore <dependency name> <ignore condition>` will remove the ignore condition of the specified dependency and ignore conditions </details> Signed-off-by:
-
- Dec 14, 2023
-
-
Andrei Sandu authored
This tool makes it easy to run parachain consensus stress/performance testing on your development machine or in CI. ## Motivation The parachain consensus node implementation spans across many modules which we call subsystems. Each subsystem is responsible for a small part of logic of the parachain consensus pipeline, but in general the most load and performance issues are localized in just a few core subsystems like `availability-recovery`, `approval-voting` or `dispute-coordinator`. In the absence of such a tool, we would run large test nets to load/stress test these parts of the system. Setting up and making sense of the amount of data produced by such a large test is very expensive, hard to orchestrate and is a huge development time sink. ## PR contents - CLI tool - Data Availability Read test - reusable mockups and components needed so far - Documentation on how to get started ### Data Availability Read test An overseer is built with using a real `availability-recovery` susbsytem instance while dependent subsystems like `av-store`, `network-bridge` and `runtime-api` are mocked. The network bridge will emulate all the network peers and their answering to requests. The test is going to be run for a number of blocks. For each block it will generate send a “RecoverAvailableData” request for an arbitrary number of candidates. We wait for the subsystem to respond to all requests before moving to the next block. At the same time we collect the usual subsystem metrics and task CPU metrics and show some nice progress reports while running. ### Here is how the CLI looks like: ``` [2023-11-28T13:06:27Z INFO subsystem_bench::core::display] n_validators = 1000, n_cores = 20, pov_size = 5120 - 5120, error = 3, latency = Some(PeerLatency { min_latency: 1ms, max_latency: 100ms }) [2023-11-28T13:06:27Z INFO subsystem-bench::availability] Generating template candidate index=0 pov_size=5242880 [2023-11-28T13:06:27Z INFO subsystem-bench::availability] Created test environment. [2023-11-28T13:06:27Z INFO subsystem-bench::availability] Pre-generating 60 candidates. [2023-11-28T13:06:30Z INFO subsystem-bench::core] Initializing network emulation for 1000 peers. [2023-11-28T13:06:30Z INFO subsystem-bench::availability] Current block 1/3 [2023-11-28T13:06:30Z INFO substrate_prometheus_endpoint]〽 ️ Prometheus exporter started at 127.0.0.1:9999 [2023-11-28T13:06:30Z INFO subsystem_bench::availability] 20 recoveries pending [2023-11-28T13:06:37Z INFO subsystem_bench::availability] Block time 6262ms [2023-11-28T13:06:37Z INFO subsystem-bench::availability] Sleeping till end of block (0ms) [2023-11-28T13:06:37Z INFO subsystem-bench::availability] Current block 2/3 [2023-11-28T13:06:37Z INFO subsystem_bench::availability] 20 recoveries pending [2023-11-28T13:06:43Z INFO subsystem_bench::availability] Block time 6369ms [2023-11-28T13:06:43Z INFO subsystem-bench::availability] Sleeping till end of block (0ms) [2023-11-28T13:06:43Z INFO subsystem-bench::availability] Current block 3/3 [2023-11-28T13:06:43Z INFO subsystem_bench::availability] 20 recoveries pending [2023-11-28T13:06:49Z INFO subsystem_bench::availability] Block time 6194ms [2023-11-28T13:06:49Z INFO subsystem-bench::availability] Sleeping till end of block (0ms) [2023-11-28T13:06:49Z INFO subsystem_bench::availability] All blocks processed in 18829ms [2023-11-28T13:06:49Z INFO subsystem_bench::availability] Throughput: 102400 KiB/block [2023-11-28T13:06:49Z INFO subsystem_bench::availability] Block time: 6276 ms [2023-11-28T13:06:49Z INFO subsystem_bench::availability] Total received from network: 415 MiB Total sent to network: 724 KiB Total subsystem CPU usage 24.00s CPU usage per block 8.00s Total test environment CPU usage 0.15s CPU usage per block 0.05s ``` ### Prometheus/Grafana stack in action <img width="1246" alt="Screenshot 2023-11-28 at 15 11 10" src="https://github.com/paritytech/polkadot-sdk/assets/54316454/eaa47422-4a5e-4a3a-aaef-14ca644c1574"> <img width="1246" alt="Screenshot 2023-11-28 at 15 12 01" src="https://github.com/paritytech/polkadot-sdk/assets/54316454/237329d6-1710-4c27-8f67-5fb11d7f66ea"> <img width="1246" alt="Screenshot 2023-11-28 at 15 12 38" src="https://github.com/paritytech/polkadot-sdk/assets/54316454/a07119e8-c9f1-4810-a1b3-f1b7b01cf357 "> --------- Signed-off-by:
-






![dependabot[bot]'s avatar](https://secure.gravatar.com/avatar/48ea49be76d0c68403a7f3df87e3487d?s=80&d=identicon "dependabot[bot]")






