- Apr 08, 2024
-
-
Aaro Altonen authored
[litep2p](https://github.com/altonen/litep2p) is a libp2p-compatible P2P networking library. It supports all of the features of `rust-libp2p` that are currently being utilized by Polkadot SDK. Compared to `rust-libp2p`, `litep2p` has a quite different architecture which is why the new `litep2p` network backend is only able to use a little of the existing code in `sc-network`. The design has been mainly influenced by how we'd wish to structure our networking-related code in Polkadot SDK: independent higher-levels protocols directly communicating with the network over links that support bidirectional backpressure. A good example would be `NotificationHandle`/`RequestResponseHandle` abstractions which allow, e.g., `SyncingEngine` to directly communicate with peers to announce/request blocks. I've tried running `polkadot --network-backend litep2p` with a few different peer configurations and there is a noticeable reduction in networking CPU usage. For high load (`...
-
- Apr 01, 2024
-
-
Alexandru Gheorghe authored
Runtime release 1.2 includes bumping of the ParachainHost APIs up to v10, so let's move all the released APIs out of vstaging folder, this PR does not include any logic changes only renaming of the modules and some moving around. Signed-off-by:Alexandru Gheorghe <[email protected]>
-
- Mar 26, 2024
-
-
Andrei Eres authored
Here we add the ability to save subsystem benchmark results in JSON format to display them as graphs To draw graphs, CI team will use [github-action-benchmark](https://github.com/benchmark-action/github-action-benchmark). Since we are using custom benchmarks, we need to prepare [a specific data type](https://github.com/benchmark-action/github-action-benchmark?tab=readme-ov-file#examples): ``` [ { "name": "CPU Load", "unit": "Percent", "value": 50 } ] ``` Then we'll get graphs like this: 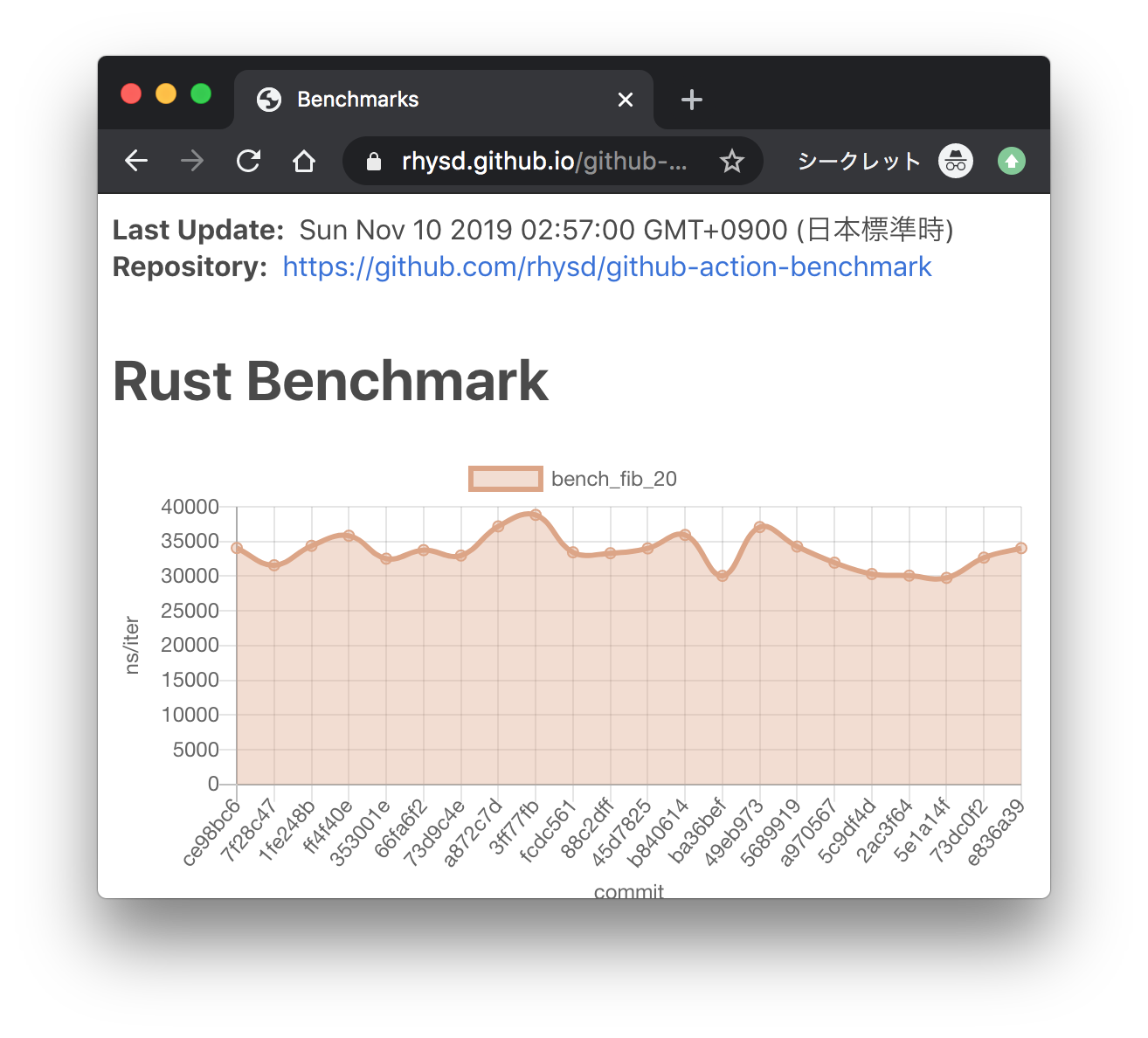 [A live page with graphs](https://benchmark-action.github.io/github-action-benchmark/dev/bench/) --------- Co-authored-by:ordian <[email protected]>
-
Dcompoze authored
**Update:** Pushed additional changes based on the review comments. **This pull request fixes various spelling mistakes in this repository.** Most of the changes are contained in the first **3** commits: - `Fix spelling mistakes in comments and docs` - `Fix spelling mistakes in test names` - `Fix spelling mistakes in error messages, panic messages, logs and tracing` Other source code spelling mistakes are separated into individual commits for easier reviewing: - `Fix the spelling of 'authority'` - `Fix the spelling of 'REASONABLE_HEADERS_IN_JUSTIFICATION_ANCESTRY'` - `Fix the spelling of 'prev_enqueud_messages'` - `Fix the spelling of 'endpoint'` - `Fix the spelling of 'children'` - `Fix the spelling of 'PenpalSiblingSovereignAccount'` - `Fix the spelling of 'PenpalSudoAccount'` - `Fix the spelling of 'insufficient'` - `Fix the spelling of 'PalletXcmExtrinsicsBenchmark'` - `Fix the spelling of 'subtracted'` - `Fix the spelling of 'CandidatePendingAvailability'` - `Fix the spelling of 'exclusive'` - `Fix the spelling of 'until'` - `Fix the spelling of 'discriminator'` - `Fix the spelling of 'nonexistent'` - `Fix the spelling of 'subsystem'` - `Fix the spelling of 'indices'` - `Fix the spelling of 'committed'` - `Fix the spelling of 'topology'` - `Fix the spelling of 'response'` - `Fix the spelling of 'beneficiary'` - `Fix the spelling of 'formatted'` - `Fix the spelling of 'UNKNOWN_PROOF_REQUEST'` - `Fix the spelling of 'succeeded'` - `Fix the spelling of 'reopened'` - `Fix the spelling of 'proposer'` - `Fix the spelling of 'InstantiationNonce'` - `Fix the spelling of 'depositor'` - `Fix the spelling of 'expiration'` - `Fix the spelling of 'phantom'` - `Fix the spelling of 'AggregatedKeyValue'` - `Fix the spelling of 'randomness'` - `Fix the spelling of 'defendant'` - `Fix the spelling of 'AquaticMammal'` - `Fix the spelling of 'transactions'` - `Fix the spelling of 'PassingTracingSubscriber'` - `Fix the spelling of 'TxSignaturePayload'` - `Fix the spelling of 'versioning'` - `Fix the spelling of 'descendant'` - `Fix the spelling of 'overridden'` - `Fix the spelling of 'network'` Let me know if this structure is adequate. **Note:** The usage of the words `Merkle`, `Merkelize`, `Merklization`, `Merkelization`, `Merkleization`, is somewhat inconsistent but I left it as it is. ~~**Note:** In some places the term `Receival` is used to refer to message reception, IMO `Reception` is the correct word here, but I left it as it is.~~ ~~**Note:** In some places the term `Overlayed` is used instead of the more acceptable version `Overlaid` but I also left it as it is.~~ ~~**Note:** In some places the term `Applyable` is used instead of the correct version `Applicable` but I also left it as it is.~~ **Note:** Some usage of British vs American english e.g. `judgement` vs `judgment`, `initialise` vs `initialize`, `optimise` vs `optimize` etc. are both present in different places, but I suppose that's understandable given the number of contributors. ~~**Note:** There is a spelling mistake in `.github/CODEOWNERS` but it triggers errors in CI when I make changes to it, so I left it as it is.~~
-
- Mar 25, 2024
-
-
Andrei Eres authored
Adds availability-write regression tests. The results for the `availability-distribution` subsystem are volatile, so I had to reduce the precision of the test.
-
- Mar 13, 2024
-
-
Andrei Eres authored
Fixes https://github.com/paritytech/polkadot-sdk/issues/3530
-
- Mar 11, 2024
-
-
Andrei Eres authored
Fixes https://github.com/paritytech/polkadot-sdk/issues/3528 ```rust latency: mean_latency_ms = 30 // common sense std_dev = 2.0 // common sense n_validators = 300 // max number of validators, from chain config n_cores = 60 // 300/5 max_validators_per_core = 5 // default min_pov_size = 5120 // max max_pov_size = 5120 // max peer_bandwidth = 44040192 // from the Parity's kusama validators bandwidth = 44040192 // from the Parity's kusama validators connectivity = 90 // we need to be connected to 90-95% of peers ```
-
- Mar 08, 2024
-
-
cuinix authored
Signed-off-by:
cuinix <[email protected]> Co-authored-by:
Bastian Köcher <[email protected]>
-
- Mar 01, 2024
-
-
Andrei Eres authored
### What's been done - `subsystem-bench` has been split into two parts: a cli benchmark runner and a library. - The cli runner is quite simple. It just allows us to run `.yaml` based test sequences. Now it should only be used to run benchmarks during development. - The library is used in the cli runner and in regression tests. Some code is changed to make the library independent of the runner. - Added first regression tests for availability read and write that replicate existing test sequences. ### How we run regression tests - Regression tests are simply rust integration tests without the harnesses. - They should only be compiled under the `subsystem-benchmarks` feature to prevent them from running with other tests. - This doesn't work when running tests with `nextest` in CI, so additional filters have been added to the `nextest` runs. - Each benchmark run takes a different time in the beginning, so we "warm up" the tests until their CPU usage differs by only 1%. - After the warm-up, we run the benchmarks a few more times and compare the average with the exception using a precision. ### What is still wrong? - I haven't managed to set up approval voting tests. The spread of their results is too large and can't be narrowed down in a reasonable amount of time in the warm-up phase. - The tests start an unconfigurable prometheus endpoint inside, which causes errors because they use the same 9999 port. I disable it with a flag, but I think it's better to extract the endpoint launching outside the test, as we already do with `valgrind` and `pyroscope`. But we still use `prometheus` inside the tests. ### Future work * https://github.com/paritytech/polkadot-sdk/issues/3528 * https://github.com/paritytech/polkadot-sdk/issues/3529 * https://github.com/paritytech/polkadot-sdk/issues/3530 * https://github.com/paritytech/polkadot-sdk/issues/3531 --------- Co-authored-by:Alexander Samusev <[email protected]>
-




