- Mar 26, 2024
-
-
Andrei Eres authored
Here we add the ability to save subsystem benchmark results in JSON format to display them as graphs To draw graphs, CI team will use [github-action-benchmark](https://github.com/benchmark-action/github-action-benchmark). Since we are using custom benchmarks, we need to prepare [a specific data type](https://github.com/benchmark-action/github-action-benchmark?tab=readme-ov-file#examples): ``` [ { "name": "CPU Load", "unit": "Percent", "value": 50 } ] ``` Then we'll get graphs like this: 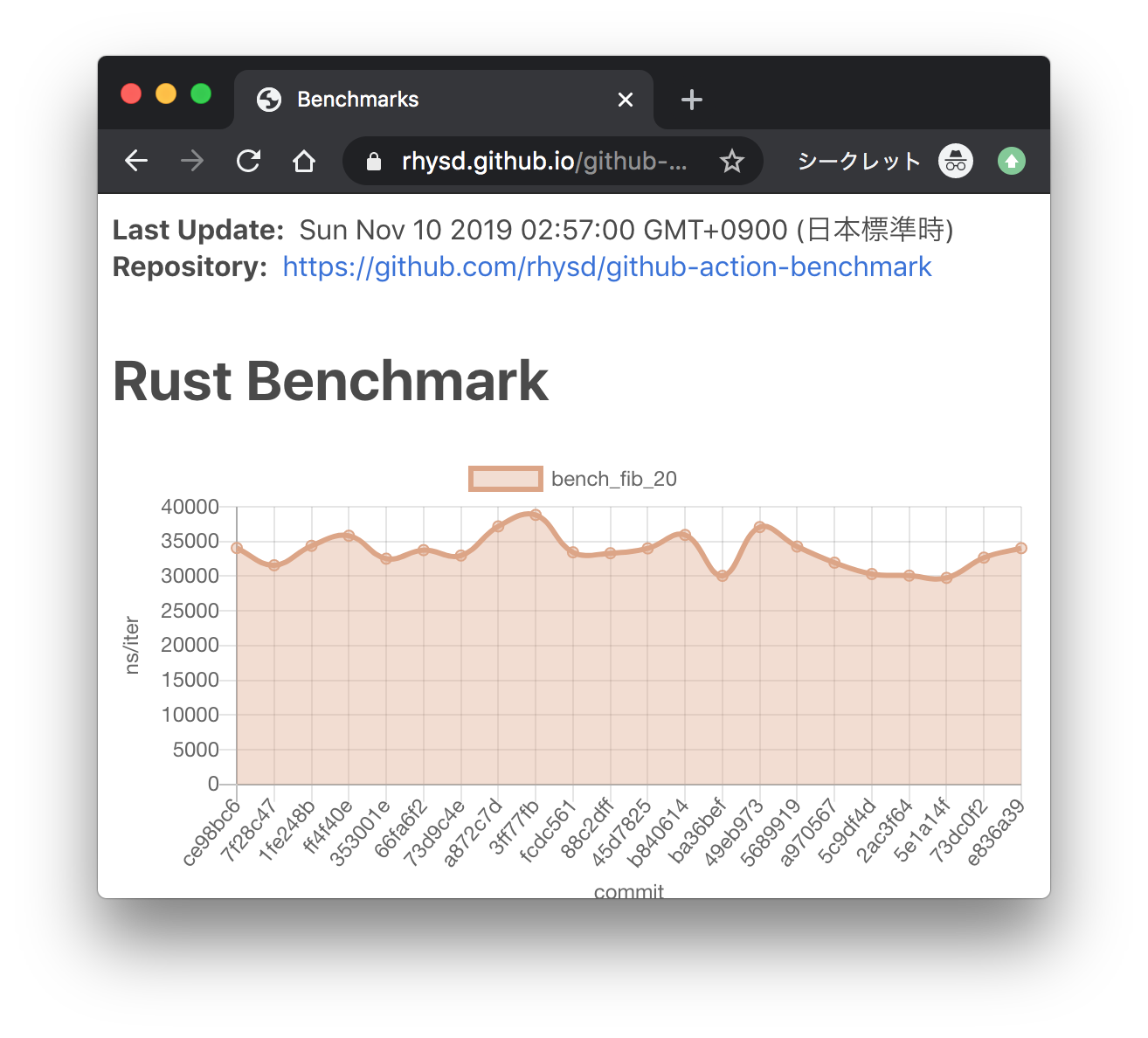 [A live page with graphs](https://benchmark-action.github.io/github-action-benchmark/dev/bench/) --------- Co-authored-by:ordian <[email protected]>
-
- Mar 25, 2024
-
-
Andrei Eres authored
Adds availability-write regression tests. The results for the `availability-distribution` subsystem are volatile, so I had to reduce the precision of the test.
-
- Mar 13, 2024
-
-
Andrei Eres authored
Fixes https://github.com/paritytech/polkadot-sdk/issues/3530
-
- Mar 01, 2024
-
-
Andrei Eres authored
### What's been done - `subsystem-bench` has been split into two parts: a cli benchmark runner and a library. - The cli runner is quite simple. It just allows us to run `.yaml` based test sequences. Now it should only be used to run benchmarks during development. - The library is used in the cli runner and in regression tests. Some code is changed to make the library independent of the runner. - Added first regression tests for availability read and write that replicate existing test sequences. ### How we run regression tests - Regression tests are simply rust integration tests without the harnesses. - They should only be compiled under the `subsystem-benchmarks` feature to prevent them from running with other tests. - This doesn't work when running tests with `nextest` in CI, so additional filters have been added to the `nextest` runs. - Each benchmark run takes a different time in the beginning, so we "warm up" the tests until their CPU usage differs by only 1%. - After the warm-up, we run the benchmarks a few more times and compare the average with the exception using a precision. ### What is still wrong? - I haven't managed to set up approval voting tests. The spread of their results is too large and can't be narrowed down in a reasonable amount of time in the warm-up phase. - The tests start an unconfigurable prometheus endpoint inside, which causes errors because they use the same 9999 port. I disable it with a flag, but I think it's better to extract the endpoint launching outside the test, as we already do with `valgrind` and `pyroscope`. But we still use `prometheus` inside the tests. ### Future work * https://github.com/paritytech/polkadot-sdk/issues/3528 * https://github.com/paritytech/polkadot-sdk/issues/3529 * https://github.com/paritytech/polkadot-sdk/issues/3530 * https://github.com/paritytech/polkadot-sdk/issues/3531 --------- Co-authored-by:Alexander Samusev <[email protected]>
-
